Demystifying LLMs with Amazon distinguished scientists

Last week, I had a chance to chat with Swami Sivasubramanian, VP of database, analytics and machine learning services at AWS. He caught me up on the broad landscape of generative AI, what we’re doing at Amazon to make tools more accessible, and how custom silicon can reduce costs and increase efficiency when training and running large models. If you haven’t had a chance, I encourage you to watch that conversation.
Swami mentioned transformers, and I wanted to learn more about how these neural network architectures have led to the rise of large language models (LLMs) that contain hundreds of billions of parameters. To put this into perspective, since 2019, LLMs have grown more than 1000x in size. I was curious what impact this has had, not only on model architectures and their ability to perform more generative tasks, but the impact on compute and energy consumption, where we see limitations, and how we can turn these limitations into opportunities.
Luckily, here at Amazon, we have no shortage of brilliant people. I sat with two of our distinguished scientists, Sudipta Sengupta and Dan Roth, both of whom are deeply knowledgeable on machine learning technologies. During our conversation they helped to demystify everything from word representations as dense vectors to specialized computation on custom silicon. It would be an understatement to say I learned a lot during our chat — honestly, they made my head spin a bit.
There is a lot of excitement around the near-infinite possibilites of a generic text in/text out interface that produces responses resembling human knowledge. And as we move towards multi-modal models that use additional inputs, such as vision, it wouldn’t be far-fetched to assume that predictions will become more accurate over time. However, as Sudipta and Dan emphasized during out chat, it’s important to acknowledge that there are still things that LLMs and foundation models don’t do well — at least not yet — such as math and spatial reasoning. Rather than view these as shortcomings, these are great opportunities to augment these models with plugins and APIs. For example, a model may not be able to solve for X on its own, but it can write an expression that a calculator can execute, then it can synthesize the answer as a response. Now, imagine the possibilities with the full catalog of AWS services only a conversation away.
Services and tools, such as Amazon Bedrock, Amazon Titan, and Amazon CodeWhisperer, have the potential to empower a whole new cohort of innovators, researchers, scientists, and developers. I’m very excited to see how they will use these technologies to invent the future and solve hard problems.
The entire transcript of my conversation with Sudipta and Dan is available below.
Now, go build!
Recommended posts
- An introduction to generative AI with Swami Sivasubramanian
- Curious about automated reasoning
- Curious about quantum computing
Transcription
This transcript has been lightly edited for flow and readability.
***
Werner Vogels: Dan, Sudipta, thank you for taking time to meet with me today and talk about this magical area of generative AI. You both are distinguished scientists at Amazon. How did you get into this role? Because it’s a quite unique role.
Dan Roth: All my career has been in academia. For about 20 years, I was a professor at the University of Illinois in Urbana Champagne. Then the last 5-6 years at the University of Pennsylvania doing work in wide range of topics in AI, machine learning, reasoning, and natural language processing.
WV: Sudipta?
Sudipta Sengupta: Before this I was at Microsoft research and before that at Bell Labs. And one of the best things I liked in my previous research career was not just doing the research, but getting it into products – kind of understanding the end-to-end pipeline from conception to production and meeting customer needs. So when I joined Amazon and AWS, I kind of, you know, doubled down on that.
WV: If you look at your space – generative AI seems to have just come around the corner – out of nowhere – but I don’t think that’s the case is it? I mean, you’ve been working on this for quite a while already.
DR: It’s a process that in fact has been going for 30-40 years. In fact, if you look at the progress of machine learning and maybe even more significantly in the context of natural language processing and representation of natural languages, say in the last 10 years, and more rapidly in the last five years since transformers came out. But a lot of the building blocks actually were there 10 years ago, and some of the key ideas actually earlier. Only that we didn’t have the architecture to support this work.
SS: Really, we are seeing the confluence of three trends coming together. First, is the availability of large amounts of unlabeled data from the internet for unsupervised training. The models get a lot of their basic capabilities from this unsupervised training. Examples like basic grammar, language understanding, and knowledge about facts. The second important trend is the evolution of model architectures towards transformers where they can take input context into account and dynamically attend to different parts of the input. And the third part is the emergence of domain specialization in hardware. Where you can exploit the computation structure of deep learning to keep writing on Moore’s Law.
SS: Parameters are just one part of the story. It’s not just about the number of parameters, but also training data and volume, and the training methodology. You can think about increasing parameters as kind of increasing the representational capacity of the model to learn from the data. As this learning capacity increases, you need to satisfy it with diverse, high-quality, and a large volume of data. In fact, in the community today, there is an understanding of empirical scaling laws that predict the optimal combinations of model size and data volume to maximize accuracy for a given compute budget.
WV: We have these models that are based on billions of parameters, and the corpus is the complete data on the internet, and customers can fine tune this by adding just a few 100 examples. How is that possible that it’s only a few 100 that are needed to actually create a new task model?
DR: If all you care about is one task. If you want to do text classification or sentiment analysis and you don’t care about anything else, it’s still better perhaps to just stay with the old machine learning with strong models, but annotated data – the model is going to be small, no latency, less cost, but you know AWS has a lot of models like this that, that solve specific problems very very well.
Now if you want models that you can actually very easily move from one task to another, that are capable of performing multiple tasks, then the abilities of foundation models come in, because these models kind of know language in a sense. They know how to generate sentences. They have an understanding of what comes next in a given sentence. And now if you want to specialize it to text classification or to sentiment analysis or to question answering or summarization, you need to give it supervised data, annotated data, and fine tune on this. And basically it kind of massages the space of the function that we are using for prediction in the right way, and hundreds of examples are often sufficient.
WV: So the fine tuning is basically supervised. So you combine supervised and unsupervised learning in the same bucket?
SS: Again, this is very well aligned with our understanding in the cognitive sciences of early childhood development. That kids, babies, toddlers, learn really well just by observation – who is speaking, pointing, correlating with spoken speech, and so on. A lot of this unsupervised learning is going on – quote unquote, free unlabeled data that’s available in vast amounts on the internet.
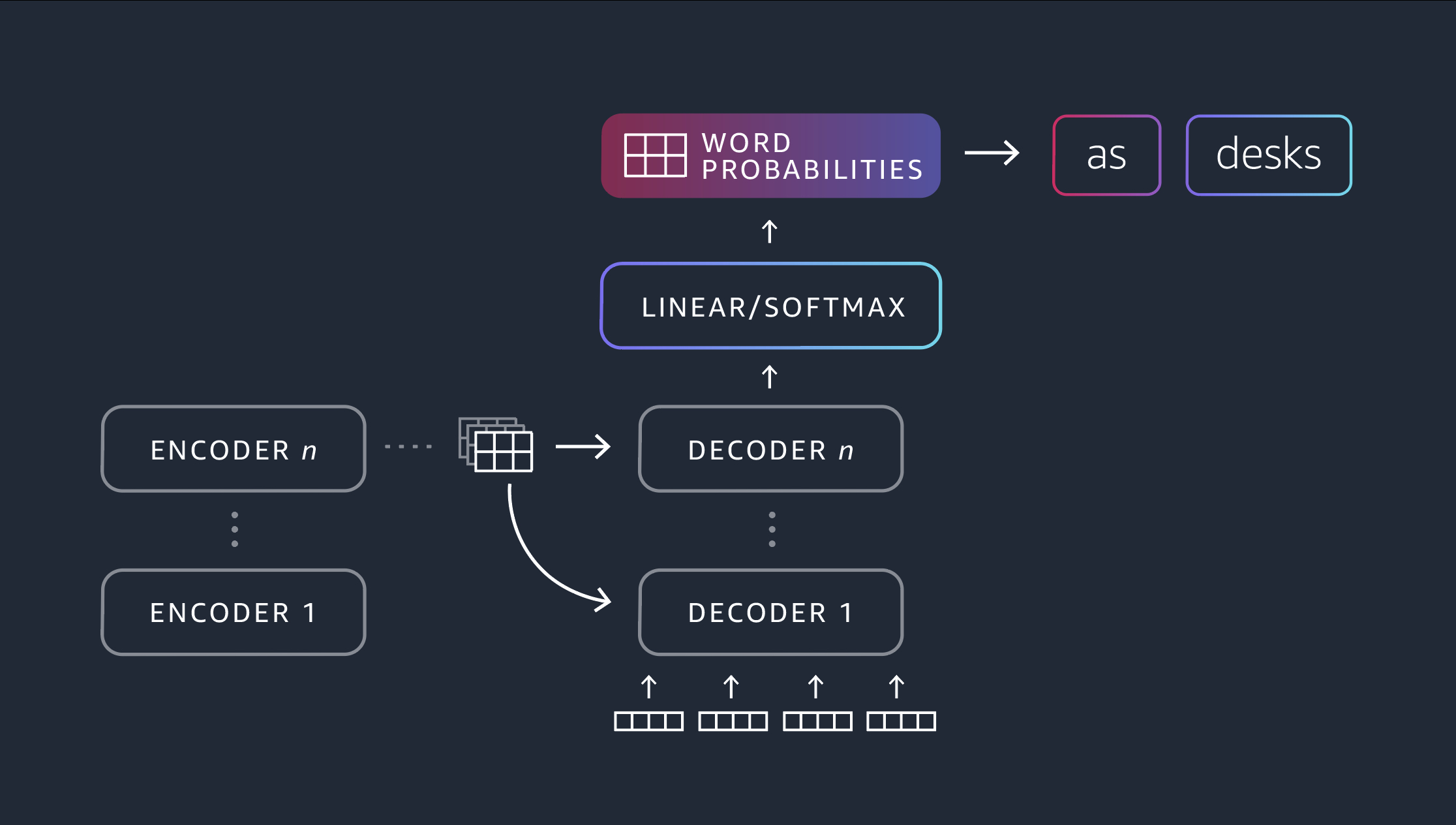
DR: One component that I want to add, that really led to this breakthrough, is the issue of representation. If you think about how to represent words, it used to be in old machine learning that words for us were discrete objects. So you open a dictionary, you see words and they are listed this way. So there is a table and there’s a desk somewhere there and there are completely different things. What happened about 10 years ago is that we moved completely to continuous representation of words. Where the idea is that we represent words as vectors, dense vectors. Where similar words semantically are represented very close to each other in this space. So now table and desk are next to each other. That that’s the first step that allows us to actually move to more semantic representation of words, and then sentences, and larger units. So that’s kind of the key breakthrough.
And the next step, was to represent things contextually. So the word table that we sit next to now versus the word table that we are using to store data in are now going to be different elements in this vector space, because they come they appear in different contexts.
Now that we have this, you can encode these things in this neural architecture, very dense neural architecture, multi-layer neural architecture. And now you can start representing larger objects, and you can represent semantics of bigger objects.
WV: How is it that the transformer architecture allows you to do unsupervised training? Why is that? Why do you no longer need to label the data?
DR: So really, when you learn representations of words, what we do is self-training. The idea is that you take a sentence that is correct, that you read in the newspaper, you drop a word and you try to predict the word given the context. Either the two-sided context or the left-sided context. Essentially you do supervised learning, right? Because you’re trying to predict the word and you know the truth. So, you can verify whether your predictive model does it well or not, but you don’t need to annotate data for this. This is the basic, very simple objective function – drop a word, try to predict it, that drives almost all the learning that we are doing today and it gives us the ability to learn good representations of words.
WV: If I look at, not only at the past five years with these larger models, but if I look at the evolution of machine learning in the past 10, 15 years, it seems to have been sort of this lockstep where new software arrives, new hardware is being built, new software comes, new hardware, and an acceleration happened of the applications of it. Most of this was done on GPUs – and the evolution of GPUs – but they are extremely power hungry beasts. Why are GPUs the best way of training this? and why are we moving to custom silicon? Because of the power?
SS: One of the things that is fundamental in computing is that if you can specialize the computation, you can make the silicon optimized for that specific computation structure, instead of being very generic like CPUs are. What is interesting about deep learning is that it’s essentially a low precision linear algebra, right? So if I can do this linear algebra really well, then I can have a very power efficient, cost efficient, high-performance processor for deep learning.
WV: Is the architecture of the Trainium radically different from general purpose GPUs?
SS: Yes. Really it is optimized for deep learning. So, the systolic array for matrix multiplication – you have like a small number of large systolic arrays and the memory hierarchy is optimized for deep learning workload patterns versus something like GPU, which has to cater to a broader set of markets like high-performance computing, graphics, and deep learning. The more you can specialize and scope down the domain, the more you can optimize in silicon. And that’s the opportunity that we are seeing currently in deep learning.
WV: If I think about the hype in the past days or the past weeks, it looks like this is the end all of machine learning – and this real magic happens, but there must be limitations to this. There are things that they can do well and things that toy cannot do well at all. Do you have a sense of that?
DR: We have to understand that language models cannot do everything. So aggregation is a key thing that they cannot do. Various logical operations is something that they cannot do well. Arithmetic is a key thing or mathematical reasoning. What language models can do today, if trained properly, is to generate some mathematical expressions well, but they cannot do the math. So you have to figure out mechanisms to enrich this with calculators. Spatial reasoning, this is something that requires grounding. If I tell you: go straight, and then turn left, and then turn left, and then turn left. Where are you now? This is something that three year olds will know, but language models will not because they are not grounded. And there are various kinds of reasoning – common sense reasoning. I talked about temporal reasoning a little bit. These models don’t have an notion of time unless it’s written somewhere.
WV: Can we expect that these problems will be solved over time?
DR: I think they will be solved.
SS: Some of these challenges are also opportunities. When a language model does not know how to do something, it can figure out that it needs to call an external agent, as Dan said. He gave the example of calculators, right? So if I can’t do the math, I can generate an expression, which the calculator will execute correctly. So I think we are going to see opportunities for language models to call external agents or APIs to do what they don’t know how to do. And just call them with the right arguments and synthesize the results back into the conversation or their output. That’s a huge opportunity.
WV: Well, thank you very much guys. I really enjoyed this. You very educated me on the real truth behind large language models and generative AI. Thank you very much.