Amazon Timestream - Time series is the new black
From the earliest days of my career, data, and the insights that we draw from that data, have always held a special place in my heart. At a company like Amazon, getting millions of items delivered to customers on demanding timeframes, and running massive world-wide data centers to host our cloud-based service offerings are all dependent on our ability to understand, process, and analyze vast quantities of data.
This is of course true in almost every industry – the ability to leverage data can be the difference between your business thriving or dying. As a technology leader, what concerns me about this is that many companies aren’t investing in the right kind of technologies that will enable them to be successful here. Take for example databases, many are still using traditional relational databases for everything, simply because they don’t know any other way. A relational database certainly has its place, but it’s often used as a hammer – a generic tool used to bluntly solve numerous problems - when in fact there are many specialized database technologies that are much better suited for a task. Like that a surgeon will have a variety of scalpels or a carpenter has dozens of drill bits, developers need data management options that can exactly meet the objectives of their business in the most effective way.
One area that we are seeing really take off is the need to track and measure data over a period of time - time series data. As individuals, we use this in everyday life all the time; If you’re trying to improve your health, you may track how many steps you take daily, and relate that to your body weight or size over time to understand how well you’re doing. This is clearly a small-scale example, but on the other end of the spectrum, large-scale time series use cases abound in our current technological landscape. Be it tracking the price of a stock or cryptocurrency that changes every millisecond, performance and health metrics of a video streaming application, sensors for reading temperature, pressure and humidity, or the information generated from millions of IoT devices. Modern digital applications require AWS customers to collect, store, and analyze time series data at extreme scale, and with performance that a relational database simply cannot provide.
Today, I’d like to go under the covers and show how customers have been building their own time series solutions on AWS, and how we built Amazon Timestream to give customers a more scalable, best in class performance option.
No more Rube Goldberg machines
When we build new services, we aim to solve tough customer problems. In the case of time series data, we found that customers were building complicated bespoke architectures using several AWS services. Prior to Timestream, a common approach to building a time series solution on AWS was to piece together something like this:
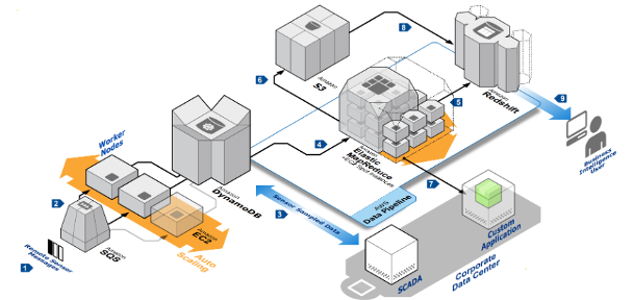
The idea here was to queue the data as it comes in, and then land it in a highly scalable, and durable store such as Amazon DynamoDB. From there, export the data to Amazon EMR in order to shape the data into a format that can satisfy each use case you have for it, use Redshift or Athena to expose the data to analytic and application specific functionality, and so on.
This was a plausible architecture for smaller-scale implementations, but as throughput needs increase, scaling this becomes a major challenge. To get the job done, customers end up landing, transforming, and moving data around repeatedly, with not just a few, but dozens of AWS services pipelined together. Looking at these solutions really feels like looking at Rube Goldberg machines. It’s staggering to see how complex architectures become in order to satisfy the needs of these workloads.
Most importantly, all of this is something that needed to be built, managed, and maintained by our customers, and it still doesn’t meet their scale and performance needs. Many time series applications we saw were generating enormous volumes of data. One common example here is video streaming. The act of delivering high quality video content is a very complex process. Understanding load latency, video frame drops, and user activity is something that needs to happen at massive scale and in real time. This process alone can generate several GBs of data every second, while easily running hundreds of thousands, sometimes over a million, queries per hour. A relational database certainly isn’t the right choice here, and the aforementioned architecture is complex to manage and still struggles to meet the needs of an application like this.
Which is exactly why we built Timestream.
How was Timestream built?
We built Amazon Timestream from the ground up for massive scale. Timestream started out by decoupling data ingestion, storage, and query such that each can scale independently. The design keeps each sub-system simple, making it easier to achieve unwavering reliability, while also eliminating scaling bottlenecks, and reducing the chances of correlated system failures which becomes more important as the system grows.
At the same time, in order to manage overall growth, the system is cell based – rather than scale the system as a whole, we segment the system into multiple smaller copies of itself (called “cells”) so that these cells can be tested at full scale, and a system problem in one cell can’t affect activity in any of the other cells. The cell-based architecture is the same approach we took with Amazon Aurora, and is a strategy that has served us well in recent years for maintaining industry leading service availability. As an aside, Peter Vosshall gave a really great talk about minimizing blast radius and our application of cell-based architectures a few years back. I highly recommend watching his talk.
Getting data in
One of the major challenges of other time series implementations is how to get a high throughput of events into the system without compromising query performance. Other time series systems struggle with this, which is why they often benchmark their performance in phases – they load the data measuring throughput and latency without queries running, and then benchmark query performance without any data being loaded at the same time. While this may have some value for raw comparisons, it is unrealistic for real workloads. Performance of a system under full workload is not equivalent to the sum of its subsystems’ performance. In fact, it is often the case that optimal performance for high scale concurrent activities against the same system is actually best achieved by designs that don’t optimize the subsystems in isolation. Recognizing this, Timestream optimizes for scaling data ingest and query load concurrently, and always tests the system with the full workload running.
On the ingest side, Timestream routes writes for a table – or rather, a partition of a table – to a fault-tolerant memory store instance that only takes writes. The memory store in turn achieves durability in a separate storage system that replicates the data across three availability zones (AZs). Replication is quorum based such that the loss of nodes, or an entire AZ, will not disrupt write availability. In near real-time, other in-memory storage nodes sync to the data in order to serve queries. The reader replica nodes span AZs as well, to ensure high read availability.
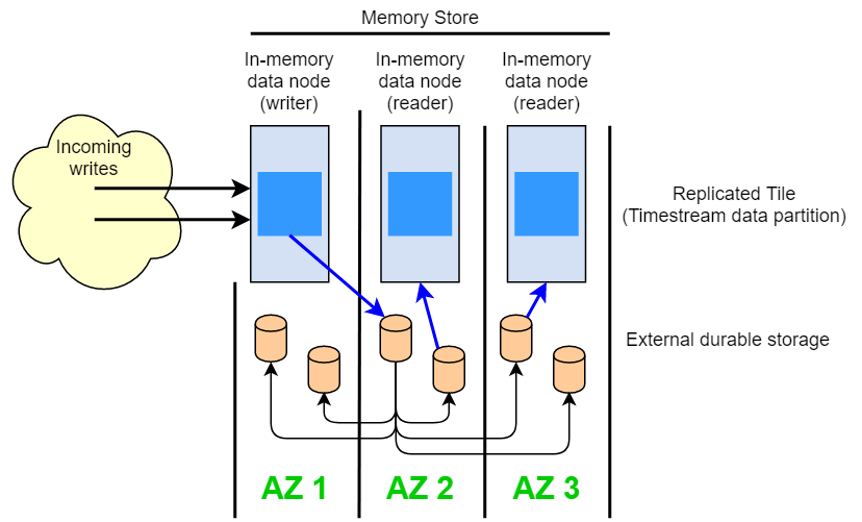
The key to achieving massive scale is then found in the partitioning scheme – an area where Timestream really shines. A single timestream table may have hundreds, thousands, or even millions of partitions. Individual partitions don’t directly communicate with each other, nor do they share any data concerning one another (shared-nothing architecture). Instead, the partitioning of a table is made sense of through a highly available partition tracking and indexing service. This implements another separation of concerns designed specifically to minimize the effect of failures in the system and make correlated failures much less likely.
When data is stored in Timestream, it is not only organized in time order, but also organizes the data across time based on context attributes written with the data. We found that having a partitioning scheme that divides “space” in addition to time to be really important for massively scaling a time series system. This is because most time series data is written at or around current time. As a result, partitioning by time alone doesn’t do a good job of distributing write traffic or allow for effective pruning of data at query time. This is a big deal for extreme scale time series processing, and it has allowed Timestream to scale orders of magnitude higher than the other leading systems out there today in serverless fashion. We call the resulting partitions “Tiles” since they represent divisions of a two-dimensional space which are designed to be of similar size – much like the tiles of a kitchen floor.
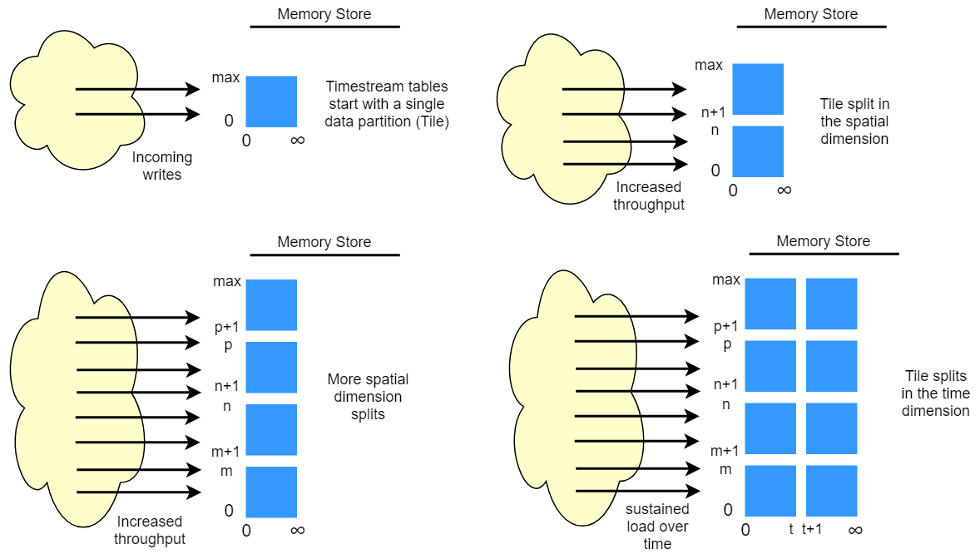
Timestream tables start out as a single partition (tile), and then split in the spatial dimension as throughput requires. When tiles reach a certain size, they then split in the time dimension in order to achieve better read parallelism as the data size grows.
Data Lifecycle
Timestream is designed to automatically manage the lifecycle of time series data. It offers two data stores – the in-memory store and a cost-effective magnetic store, and it supports configuring table level policies to automatically transfer data across stores. Incoming writes land in the memory store where data is optimized for writes, as well as reads performed around current time for powering dashboard and alerting type queries. When the main time-frame for writes, alerting, and dashboarding needs has passed, allowing the data to automatically flow from the memory store to the magnetic store optimizes costs.
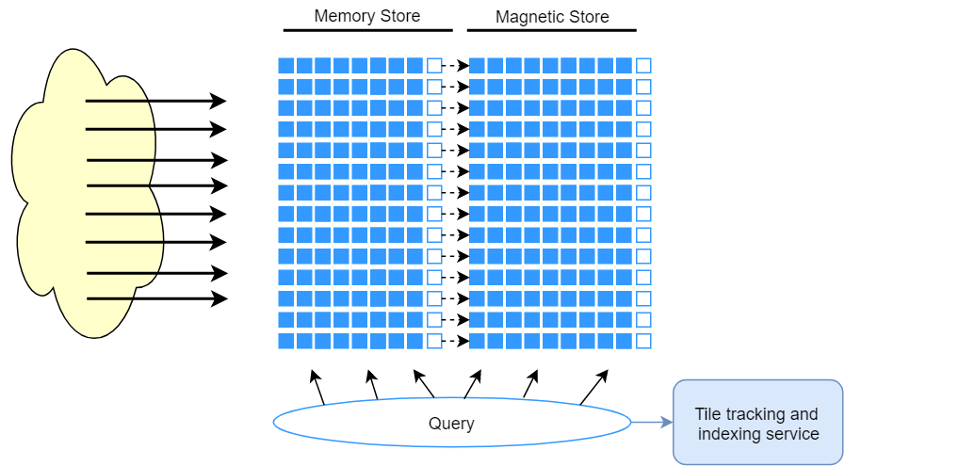
Timestream allows setting a data retention policy on the memory store for this purpose.
Once the data moves to the magnetic store, it is reorganized into a format that is highly optimized for large volume data reads. The magnetic store also has a data retention policy that may be configured if there is a time threshold where the data outlives its usefulness. When the data exceeds the time range defined for the magnetic store retention policy, it is automatically removed. I’ve seen customers painstakingly build these life cycle mechanisms into their Rube Goldberg machines, and they find this stuff extremely difficult to get right. With Timestream, other than some configuration, the data lifecycle management occurs seamlessly behind the scenes. This has turned out to be one of the features that our “Rube Goldberg” solution customers find extremely valuable, as previously they had to transform and move data on their own which is complicated, and error-prone in one-off solutions.
Query
Timestream queries are expressed in a SQL grammar that has extensions for time series-specific support (time series-specific data types and functions), so the learning curve is easy for developers already working with SQL. Queries are then processed by an adaptive, distributed query engine that uses metadata from the tile tracking and indexing service to seamlessly access and combine data across data stores at the time the query is issued. This makes for an experience that resonates well with customers as it collapses many of the Rube Goldberg complexities into a simple and familiar database abstraction.
Queries are run by a dedicated fleet of workers where the number of workers enlisted to run a given query is determined by query complexity and data size. Performance for complex queries over large data sets is achieved through massive parallelism, both on the query execution fleet and the storage fleets of the system. The ability to analyze massive amounts of data quickly and efficiently is one of Timestream’s greatest strengths. A single query executing over terabytes or even petabytes of data may have thousands of machines working on it all at the same time.
Engineered to perform in today’s (and tomorrow’s) data-driven world
The world today is increasing rapidly in the amount, and use of time series data, driven by instrumenting/monitoring everything on earth and beyond, connecting at very high bandwidth (5G et al), and leveraging of the data using ML/AI-driven analyses. Now, when customers need to process, manage, and analyze large quantities of time series data, they no longer need to build and maintain a Rube Goldberg machine – with Timestream, AWS takes on all of the complexity, and customers can just focus on what they want to get out of the data.