How Amazon is solving big-data challenges with data lakes

Back when Jeff Bezos filled orders in his garage and drove packages to the post office himself, crunching the numbers on costs, tracking inventory, and forecasting future demand was relatively simple. Fast-forward 25 years, Amazon's retail business has more than 175 fulfillment centers (FC) worldwide with over 250,000 full-time associates shipping millions of items per day.
Amazon's worldwide financial operations team has the incredible task of tracking all of that data (think petabytes). At Amazon's scale, a miscalculated metric, like cost per unit, or delayed data can have a huge impact (think millions of dollars). The team is constantly looking for ways to get more accurate data, faster.
That's why, in 2019, they had an idea: Build a data lake that can support one of the largest logistics networks on the planet. It would later become known internally as the Galaxy data lake. The Galaxy data lake was built in 2019 and now all the various teams are working on moving their data into it.
A data lake is a centralized secure repository that allows you to store, govern, discover, and share all of your structured and unstructured data at any scale. Data lakes don't require a pre-defined schema, so you can process raw data without having to know what insights you might want to explore in the future. The following figure shows the key components of a data lake.
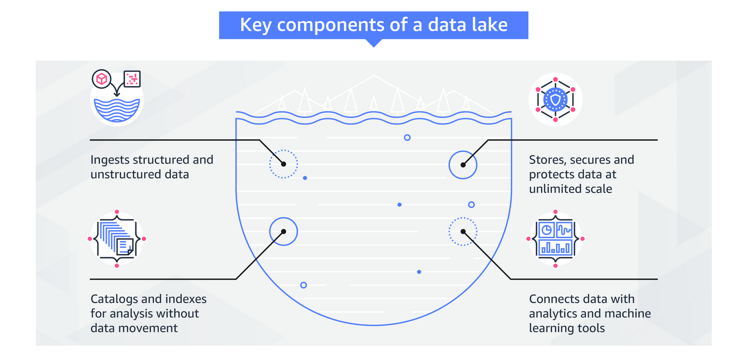
The challenges of big data
The challenges Amazon has faced with big data are similar to the challenges many other companies face: data silos, difficulty analyzing diverse datasets, data controllership, data security, and incorporating machine learning (ML). Let's take a closer look at these challenges and see how a data lake can help solve them.
Breaking down silos
A major reason companies choose to create data lakes is to break down data silos. Having pockets of data in different places, controlled by different groups, inherently obscures data. This often happens when a company grows fast and/or acquires new businesses. In the case of Amazon, it's been both.
To expand internationally and create new shipping programs quickly (for example, FREE Same-Day Delivery or Amazon Fresh), most operations planning teams have been in control of their own data and technology. As a result, data is stored in different places and in different ways. This approach allows each team to tackle problems, respond to customer needs, and innovate faster. However, it's harder to make sense of the data at an organizational and company-wide level—it requires manual data collection from many different sources. With so many teams operating independently, we lose efficiencies that could be achieved by solving problems together.
It's also difficult to get granular details from the data, because not everybody has access to the various data repositories. For smaller queries, you could share a cut of the data in a spreadsheet. But challenges arise when data exceeds the capacity of a spreadsheet (which often happens for larger companies). In some cases, you could share a higher-level summary of the data, but then you're really not getting the full picture.
A data lake solves this problem by uniting all the data into one central location. Teams can continue to function as nimble units, but all roads lead back to the data lake for analytics. No more silos.
Analyzing diverse datasets
Another challenge of using different systems and approaches to data management is that the data structures and information vary. For example, Amazon Prime has data for fulfillment centers and packaged goods, while Amazon Fresh has data for grocery stores and food. Even shipping programs differ internationally. For example, different countries sometimes have different box sizes and shapes. There's also an increasing amount of unstructured data coming from Internet of Things (IoT) devices (like sensors on fulfillment center machines).
What's more, different systems may also have the same type of information, but it's labeled differently. For example, in Europe, the term used is "cost per unit," but in North America, the term used is "cost per package." The date formats of the two terms are different. In this instance, a link needs to be made between the two labels so people analyzing the data know it refers to the same thing.
If you wanted to combine all of this data in a traditional data warehouse without a data lake, it would require a lot of data preparation and export, transform, and load (ETL). You would have to make trade-offs on what to keep and what to lose and continually change the structure of a rigid system.
Data lakes allow you to import any amount of data in any format because there is no pre-defined schema. You can even ingest data in real time. You can collect data from multiple sources and move it into the data lake in its original format. You can also build links between information that might be labeled differently but represents the same thing. Moving all your data to a data lake also improves what you can do with a traditional data warehouse. You have the flexibility to store highly structured, frequently accessed data in a data warehouse, while also keeping up to exabytes of structured, semi-structured, and unstructured data in your data lake storage.
Managing data access
With data stored in so many locations, it's difficult to both access all of it and to link to external tools for analysis. Amazon's operations finance data is spread across more than 25 databases with regional teams creating their own local version of datasets. That means over 25 access management credentials for some people. Many of the databases require access management support to do things like change profiles or reset passwords. In addition, audits and controls must be in place for each database to ensure that nobody has improper access.
With a data lake, it's easier to get the right data to the right people at the right time. Instead of managing access for all the different locations in which data is stored, you only have to worry about one set of credentials. Data lakes have controls that allow authorized users to see, access, process, and/or modify specific assets. Data lakes help ensure that unauthorized users are blocked from taking actions that would compromise data confidentiality and security.
With a data lake, data is stored in an open format, which makes it easier to work with different analytic services. Open format also makes it more likely for the data to be compatible with tools that don't even exist yet. Various roles in your organization, like data scientists, data engineers, application developers, and business analysts, can access data with their choice of analytic tools and frameworks.
You're not locked in to a small set of tools, and a broader group of people can make sense of the data.
Accelerating machine learning
A data lake is a powerful foundation for ML and AI (artificial intelligence), because ML and AI thrive on large, diverse datasets. ML uses statistical algorithms that learn from existing data, a process called training, to make decisions about new data, a process called inference. During training, patterns and relationships in the data are identified to build a model. The model allows you to make intelligent decisions about data it hasn't encountered before. The more data you have the better you can train your ML models, resulting in improved accuracy.
One of the biggest responsibilities of Amazon's worldwide operations finance team is planning and forecasting operating costs and capital expenditure for Amazon's supply chain, which includes the entire transportation network, hundreds of fulfillment centers, sort centers, delivery stations, Whole Foods locations, Fresh pick-up points, and more. They help answer important high-level questions, like "How many packages will we ship next year?" and "How much will we spend on salaries?" They also address very specific questions, like "How many boxes of each size do we need in Tampa, FL next month?"

The more accurate your forecast is, the better. If you estimate too low or too high, it can have negative consequences that affect your customers and your bottom line. For example, at Amazon, if we forecast demand too low, warehouse workers at a fulfillment center might not have enough supplies or there might not be enough drivers, which could lead to packages being delayed, more calls to customer service, orders being cancelled, and loss of customer trust. If we forecast too high, you could have inventory and boxes sitting around taking up valuable space in a warehouse. This situation means there's less room for products that are higher in demand.
Most organizations, like Amazon, spend a lot of time trying to predict the future. Luckily, ML can improve forecasts. Last year, the Amazon operations finance team did a test. They took a subset of their forecasts and compared their traditional manual process against Amazon Forecast, a fully managed service that uses machine learning to deliver highly accurate forecasts. In this trial run, the forecasts completed by Forecast were 67% more accurate on average than the forecasts completed by the manual process.
By moving all the data to a data lake, Amazon's operations finance team can combine datasets to train and deploy more accurate models. Training ML models with more relevant data increases the accuracy of forecasting. In addition, it frees employees who were performing this task manually to work on more strategic projects, like analyzing the forecasts to drive operations improvements in the field.
Using the right tools: Galaxy on AWS
Amazon's retail business uses some technology that predates the creation of Amazon Web Services (AWS), which started in 2006. To become more scalable, efficient, performant, and secure, many workloads in Amazon's retail business have moved to AWS over the last decade. The Galaxy data lake is a critical component of a larger big data platform known internally as Galaxy. The figure below shows some of the ways Galaxy relies on AWS and some of the AWS services it uses.
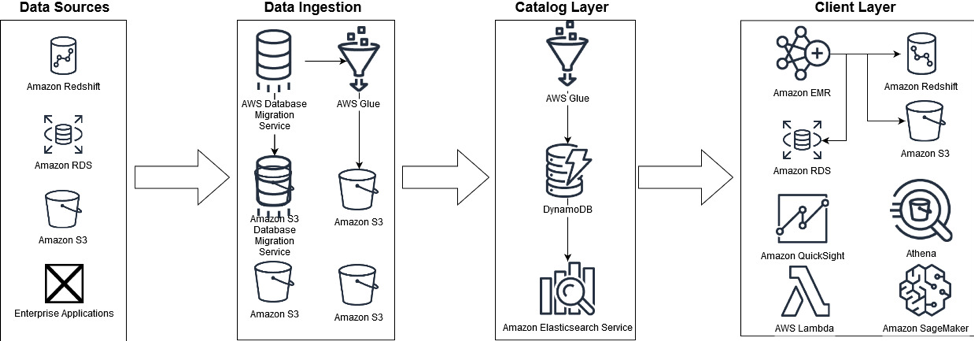
The Galaxy data lake is built on Amazon Simple Storage Service (Amazon S3), an object storage service that offers unmatched availability, durability, and scalability. Some data is also housed on Amazon proprietary file-based data stores, Andes and Elastic Data eXchange, both of which are service layers on top of Amazon S3. Some other data sources are Amazon Redshift, a data warehouse, Amazon Relational Database Service (Amazon RDS), a relational database, and enterprise applications.
AWS Glue, a fully managed ETL service that makes it easy for you to prepare and load data for analytics, and AWS Database Migration Service (AWS DMS) are used to onboard the various data sets to Amazon S3. Galaxy combines metadata assets from multiple services, including Amazon Redshift, Amazon RDS, and the AWS Glue Data Catalog, into a unified catalog layer built on Amazon DynamoDB, a key-value and document database. Amazon Elasticsearch Service (Amazon ES) is used to enable faster search queries on the catalog.
After the data has been cataloged (onboarded), various services are used at the client layer. For example, Amazon Athena, an interactive query service, for ad hoc exploratory queries using standard SQL; Amazon Redshift, a service for more structured queries and reporting; and Amazon SageMaker, for machine learning.
AWS Lake Formation
The Amazon team created the Galaxy data lake architecture from the ground up. They had to develop many of the components manually over months, which is similar to how other companies have had to do this in the past. In August 2019, AWS released a new service called AWS Lake Formation. It allows you to streamline the data lake creation process and build a secure data lake in days instead of months. Lake Formation helps you collect and catalog data from databases and object storage, move the data into your new Amazon S3 data lake, clean and classify your data using machine learning algorithms, and secure access to your sensitive data.
Summary
By storing data in a unified repository in open standards-based data formats, data lakes allow you to break down silos, use a variety of analytics services to get the most insights from your data, and cost-effectively grow your storage and data processing needs over time.
For Amazon's financial operations team, the Galaxy data lake will provide an integrated experience for its worldwide users. The infrastructure for Galaxy was built in 2019, and now the various database systems are moving into the data lake. The teams using the tool now are already seeing its benefits, citing the removal of manual processes and clunky spreadsheets, an increase in productivity, and having more time available for value-added analysis. I look forward to following the team's progress this year to see how the data lake continues to get them better data, faster.
If you're interested in breaking down data silos, performing advanced data analysis, increasing data accessibility, and accelerating machine learning, you can learn more about Data Lakes and Analytics on AWS on our website. You can also access the AWS Data Lakes & Analytics learning path online.
Originally posted on SiliconANGLE