The power of relationships in data

Have you ever received a call from your bank because they suspected fraudulent activity? Most banks can automatically identify when spending patterns or locations have deviated from the norm and then act immediately. Many times, this happens before victims even noticed that something was off. As a result, the impact of identity theft on a person's bank account and life can be managed before it's even an issue.
Having a deep understanding of the relationships in your data is powerful like that.
Consider the relationships between diseases and gene interactions. By understanding these connections, you can search for patterns within protein pathways to find other genes that may be associated with a disease. This kind of information could help advance disease research.
The deeper the understanding of the relationships, the more powerful the insights. With enough relationship data points, you can even make predictions about the future (like with a recommendation engine). But as more data is connected, and the size and complexity of the connected data increases, the relationships become more complicated to store and query.
In August, I wrote about modern application development and the value of breaking apart one-size-fits-all monolithic databases into purpose-built databases. Purpose-built databases support diverse data models and allow customers to build use case–driven, highly scalable, distributed applications. Navigating relationships in data is a perfect example of why having the right tool for a job matters. And a graph database is the right tool for processing highly connected data.
Graph data models
In a graph data model, relationships are a core part of the data model, which means you can directly create a relationship rather than using foreign keys or join tables. The data is modeled as nodes (vertices) and links (edges). In other words, the focus isn't on the data itself but how the data relates to each other. Graphs are a natural choice for building applications that process relationships because you can represent and traverse relationships between the data more easily.
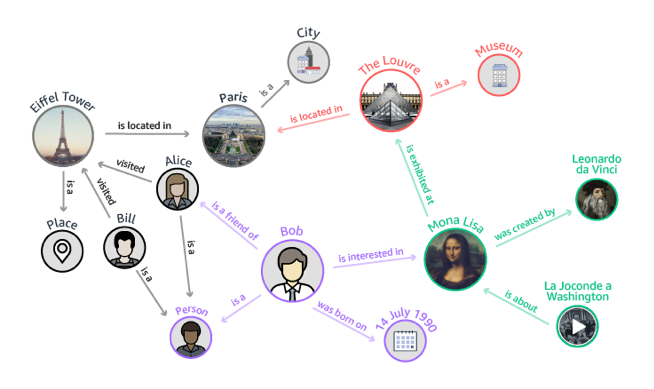
Nodes are usually a person, place, or thing, and links are how they are all connected. For example, in the following diagram, Bob is a node, the Mona Lisa is a node, and the Louvre is a node. They are connected by many different relationships. For example, Bob is interested in the Mona Lisa, the Mona Lisa is located in the Louvre, and the Louvre is a museum. This example graph is a knowledge graph. It could be used to help someone who is interested in the Mona Lisa discover other works of art by Leonardo da Vinci in the Louvre.
Applications that process relationships
A graph is a good choice when you must create relationships between data and quickly query those relationships. A knowledge graph is one example of a good use case. Here are a few more:
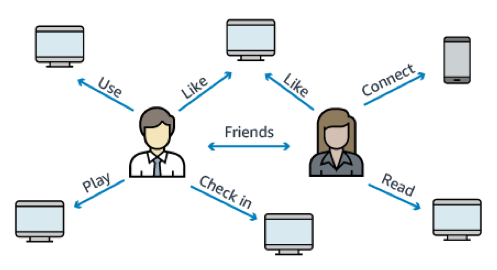
Social networking
Social networking applications have large sets of user profiles and interactions to track. For example, you might be building a social feed into your application. Use a graph to provide results that prioritize showing users the latest updates from their family, from friends whose updates they 'Like,' and from friends who live close to them.
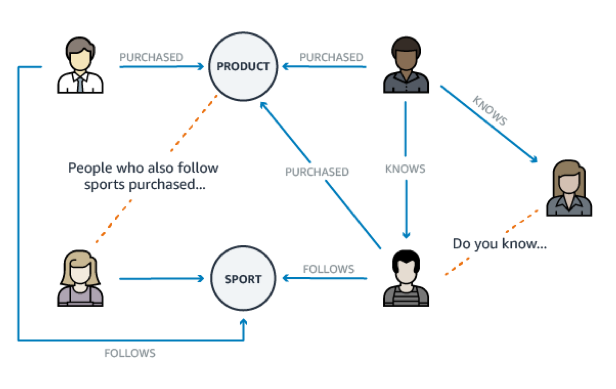
Recommendation engines
Recommendation engines store relationships between information, such as customer interests, friends, and purchase history. With a graph, you can quickly query it to make recommendations that are personalized and relevant to your users.
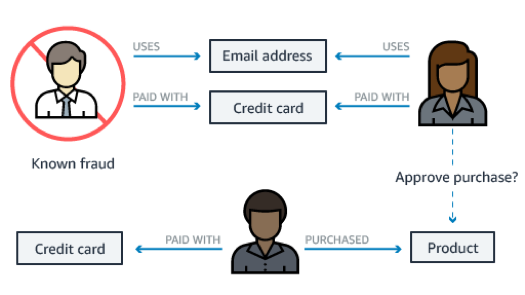
Fraud detection
If you're building a retail fraud detection application, a graph helps you build queries to easily detect relationship patterns. An example might be multiple people associated with a personal email address, or multiple people sharing the same IP address but residing in different physical addresses.
The challenges of storing a graph
Graphs can be stored in many different ways: a relational database, key value store, or graph database. Many people start using graphs with a small-scale prototype. This typically starts out well but becomes challenging as the data scale increases. Graph-based workloads tend to have a high degree of random access. The number of nodes visited increases significantly as you traverse relationships (graph fan-out), and the data required to answer a graph query are often not cached in memory (non-locality). Even seemingly simple graph queries can require accessing and scanning a large amount of data. This means that scaling and operating graph databases often requires significant manual performance tuning and optimization.
People who use a relational database or a key value store for a graph must use SQL joins (or an equivalent) to query the relationships. Because joins can execute slowly, they often must denormalize their data model (in other words, improve read performance at the expense of write performance). However, with a denormalized data model, each new relationship added requires a data model change and reduces the pace of development.
Graph databases are purpose-built to store graphs and allow data in the nodes to be directly linked and the relationships to be directly queried. This makes it easy to create new relationships without data denormalization, and makes it easier for developers to update their data models for applications that must query highly connected data. It dramatically improves query performance for navigating data relationships.
A purpose-built graph database
Last year, AWS launched Amazon Neptune, a fast, reliable, purpose-built graph database that's optimized for processing the relationships that are found in highly connected data. Neptune is a fully managed graph service that provides high availability by replicating six copies of your data across three Availability Zones. It supports up to 15 low latency read replicas to query the graph with milliseconds latency and scales storage automatically to store billions of relationships.
We've continued to innovate since Neptune's launch. Last week, at AWS re:Invent 2019, we announced the Amazon Neptune Workbench. Now you can create a Jupyter notebook, an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text, from the AWS Management Console. Once the notebook has been created, you can query the graph database with Gremlin or SPARQL Protocol and RDF Query Language (SPARQL). Neptune's recently added support for Streams and Search make it easy to connect your graph with other application building blocks. Neptune Streamsprovides an easy way to capture changes in your graph and enable integration with other purpose-built databases. When text search is the right tool for the job, Neptune now allows you to use an external text index for your Gremlin or SPARQL graph queries.
It's been fascinating to watch our customers use Neptune. We expected them to build social, fraud detection, and recommendation-type solutions using Neptune, and customers like Nike, Activision, and NBC Universal are in production with these applications on Neptune today.
However, an interesting thing happens when you give developers high performance and specialized tools for a particular job—they start finding new and exciting things to build. From knowledge graphs to identity resolution, customers have shown that they can use graphs to build interesting new applications. Thomson Reuters is using graph to understand complex regulatory models. Netflix has improved data infrastructure reliability by using a graph-based system to build and scale data lineage. And Zeta Global has built a customer intelligence platform that uses graph-based identity resolution to relate multiple devices and users.
Taking the long view: two model support
We have known that graphs are an effective way to model relationships, and the value of analyzing relationships is not new. In fact, network databases predate relational ones. Early usage of graph databases was largely in academic or public sector applications, which were research-oriented or highly specialized (such as semantic data management or complex telecommunications analysis). However, these solutions were not widespread, and graph databases have not yet become a mainstream database option for developers.
As such, we expected Neptune to be an important service for some customers. We took the long view that applications using the relationships in data are strategic, and that customers would come to adopt it over time as they had more data and more connected data.
As an example of this long view, there are two primary models when implementing for graphs—property graphs (PG) and the W3C Resource Description Framework (RDF). Both graphs consist of nodes (sometimes called "vertices") and directed edges (sometimes called "links"). Both graphs allow properties (attribute/value pairs) to be associated with nodes. Property graphs also allow these for edges, while RDF graphs treat node properties as simply more edges (though there are several techniques to express edge properties in RDF). Because of this difference, data models in the respective graphs end up looking slightly different.
There are good reasons for why these differences exist in the first place. Property graphs resemble conventional data structures in an isolated application or use case, whereas RDF graphs were originally developed to support interoperability and interchange across independently developed applications. RDF graphs can be represented as "triples" (edge starting point, label, and end point—typically referred to as "subject," "predicate," and "object"), and RDF graph databases are also called "triple stores."
Today, property graph support is available through popular open source and vendor-supported implementations, but no open standards exist for schema definition, query languages, or data interchange formats. RDF, on the other hand, is part of a suite of standardized specifications from W3C, building on other existing web standards. Those standards are collectively referred to as Semantic Web, or Linked Data. These specifications include schema languages (RDFS and OWL), a declarative query language (SPARQL), serialization formats, and a host of supporting specifications (for example, how to map relational databases to RDF graphs). The W3C specifications also describe a standardized framework for inference (for example, how to draw conclusions from data represented in graph form).
What we've found is that developers ultimately just want to do graphs, and they need both models. We see customers that start with an isolated application as a property graph, but then discover they must interoperate with other systems. We see customers that build for interoperability and interchange with RDF, but then have to build independent, business-specific applications over the aligned data in a property graph. We made an explicit choice with Neptune to support both property graph and RDF, so that you can choose whichever is best for you.
Putting together the building blocks
The innovative ways in which our customers use Neptune are great examples of what happens when developers have the right tool for a job. The reason AWS has the most purpose-built databases of any cloud provider is so that customers have more choices and freedom. In addition to graph, you might have other datasets that work better in a different database type, like relational, time series, or in-memory. That's fine too—that's modern application development.
For example, Neptune is part of the toolkit that we use to continually expand Alexa's knowledge graph for tens of millions of customers. Alexa also uses other databases, like Amazon DynamoDB for key-value and document data and Amazon Aurora for relational data. Different types of data come with different types of challenges, and picking the right database for each unique use case allows for greater speed and flexibility.
For highly connected data, a graph database makes it easy understand the relationships in your data to gain new insights. Using a graph data model, developers can quickly build applications that must query highly connected data. And a purpose-built graph database dramatically improves query performance for navigating relationships. Because developers ultimately just want to do graphs, you can choose to do fast Apache TinkerPop Gremlin traversals for property graph or tuned SPARQL queries over RDF graphs. In addition, you have access to reference architectures, code examples, and examples.
To learn more about harnessing the relationships in your data, see Amazon Neptune.