Amazon Aurora ascendant: How we designed a cloud-native relational database

Relational databases have been around for a long time. The relational model of data was pioneered back in the 1970s by E.F. Codd. The core technologies underpinning the major relational database management systems of today were developed in the 1980–1990s. Relational database fundamentals, including data relationships, ACID (Atomicity, Consistency, Isolation, Durability) transactions, and the SQL query language, have stood the test of time. Those fundamentals helped make relational databases immensely popular with users everywhere. They remain a cornerstone of IT infrastructure in many companies.
This is not to say that a system administrator necessarily enjoys dealing with relational databases. For decades, managing a relational database has been a high-skill, labor-intensive task. It's a task that requires the undivided attention of dedicated system and database administrators. Scaling a relational database while maintaining fault tolerance, performance, and blast radius size (the impact of a failure) has been a persistent challenge for administrators.
At the same time, modern internet workloads have become more demanding and require several essential properties from infrastructure:
- Users want to start with a small footprint and then grow massively without infrastructure limiting their velocity.
- In large systems, failures are a norm, not an exception. Customer workloads must be insulated from component failures or face system failures.
- Small blast radius. No one wants a single system failure to have a large impact on their business.
These are hard problems, and solving them requires breaking away from old-guard relational database architectures. When Amazon was faced with the limitations of old-guard relational databases like Oracle, we created a modern relational database service, Amazon Aurora.
Aurora's design preserves the core transactional consistency strengths of relational databases. It innovates at the storage layer to create a database built for the cloud that can support modern workloads without sacrificing performance. Customers love this because Aurora provides the performance and availability of commercial grade databases at 1/10th the cost. Since Aurora's original release, it has been the fastest-growing service in the history of AWS.
In this post, I'd like to give you a peek under the hood at how we built Aurora. I'll also discuss why customers are adopting it faster than any other service in AWS history.
Relational databases reimagined
Consider the old-guard relational database architecture:
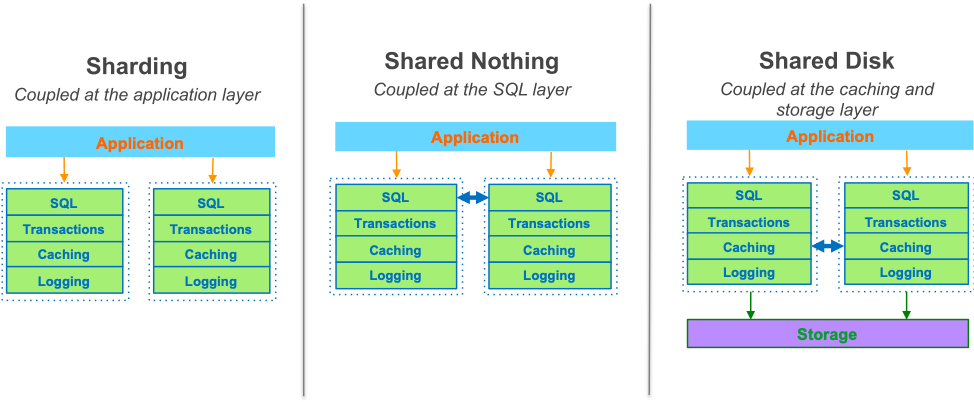
This monolithic relational database stack hadn't changed much in the last 30–40 years. While different conventional approaches exist for scaling out databases (for example, sharding, shared nothing, or shared disk), all of them share the same basic database architecture. None solve the performance, resiliency, and blast radius problems at scale, because the fundamental constraint of the tightly coupled, monolithic stack remains.
To start addressing the limitations of relational databases, we reconceptualized the stack by decomposing the system into its fundamental building blocks. We recognized that the caching and logging layers were ripe for innovation. We could move these layers into a purpose-built, scale-out, self-healing, multitenant, database-optimized storage service. When we began building the distributed storage system, Amazon Aurora was born.
We challenged the conventional ideas of caching and logging in a relational database, reinvented the database I/O layer, and reaped major scalability and resiliency benefits. Amazon Aurora is remarkably scalable and resilient, because it embraces the ideas of offloading redo logging, cell-based architecture, quorums, and fast database repairs.
Offloading redo logging: The log is the database
Traditional relational databases organize data in pages, and as pages are modified, they must be periodically flushed to disk. For resilience against failures and maintenance of ACID semantics, page modifications are also recorded in redo log records, which are written to disk in a continuous stream. While this architecture provides the basic functionality needed to support a relational database management system, it's rife with inefficiencies. For example, a single logical database write turns into multiple (up to five) physical disk writes, resulting in performance problems.
Database admins try to combat the write amplification problem by reducing the frequency of page flushes. This in turn worsens the problem of crash recovery duration. A longer interval between flushes means more redo log records to read from disk and apply to reconstruct the correct page image. That results in a slower recovery.
In Amazon Aurora, the log is the database. Database instances write redo log records to the distributed storage layer, and the storage takes care of constructing page images from log records on demand. Database instances never have to flush dirty pages, because the storage layer always knows what pages look like. This improves several performance and reliability aspects of the databases. Write performance is greatly improved due to the elimination of write amplification and the use of a scale-out storage fleet.
For example, Amazon Aurora MySQL-compatible edition demonstrates 5x write IOPS on the SysBench benchmark compared to Amazon RDS for MySQL running on similar hardware. Database crash recovery time is cut down dramatically, because a database instance no longer has to perform a redo log stream replay. The storage layer takes care of redo log application on page reads, resulting in a new storage service free from the constraints imposed by a legacy database architecture, so you can innovate even further.
Cell-based architecture
As I said before, everything fails all the time. Components fail, and fail often, in large systems. Entire instances fail. Network failures can isolate significant chunks of infrastructure. Less often, an entire data center can become isolated or go down due to a natural disaster. At AWS, we engineer for failure, and we rely on cell-based architecture to combat issues before they happen.
AWS has multiple geographical Regions (20 and counting), and within each Region, we have several Availability Zones. Leveraging multiple Regions and zones allows a well-designed service to survive both run-of-the-mill component failures and larger disasters without affecting service availability. Amazon Aurora replicates all writes to three zones to provide superior data durability and availability. In fact, Aurora can tolerate the loss of an entire zone without losing data availability, and can recover rapidly from larger failures.
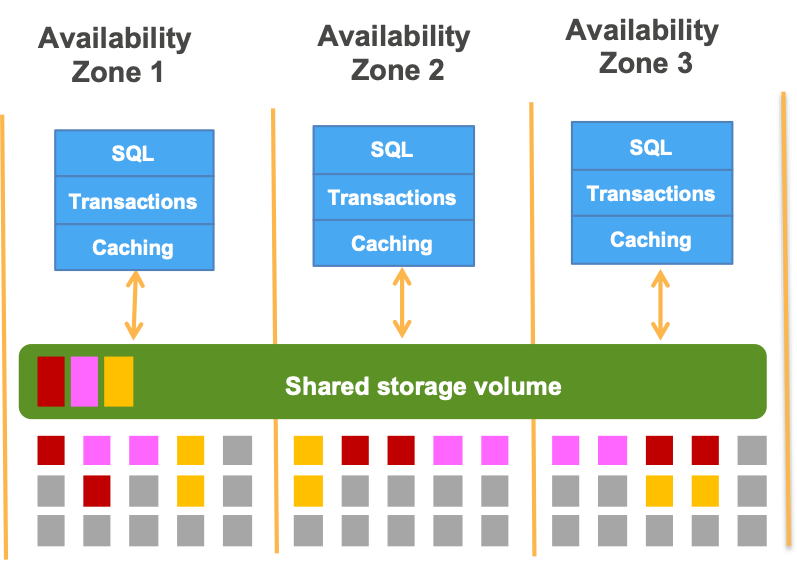
However, replication is well-known to be resource-intensive, so what makes it possible for Aurora to provide robust data replication while also offering high performance? The answer lies in quorums.
The beauty of quorums
Everything fails all the time. The larger the system, the larger the probability that something is broken somewhere: a network link, an SSD, an entire instance, or a software component. Even when a software component is bug-free, it still needs periodic restarts for upgrades.
The traditional approaches of blocking I/O processing until a failover can be carried out—and operating in "degraded mode" when a faulty component is present—are problematic at scale. Applications often don't tolerate I/O hiccups well. With moderately complex math, it can be demonstrated that, in a large system, the probability of operating in degraded mode approaches 1 as the system size grows. And then, there's the truly insidious problem of "gray failures." These occur when components do not fail completely, but become slow. If the system design does not anticipate the lag, the slow cog can degrade the performance of the overall system.
Amazon Aurora uses quorums to combat the problems of component failures and performance degradation. The basic idea of a write quorum is simple: write to as many replicas as appropriate to ensure that a quorum read always finds the latest data. The most basic quorum example is "2 out of 3":
For example, you might have three physical writes to perform with a write quorum of 2. You don't have to wait for all three to complete before the logical write operation is declared a success. It's OK if one write fails, or is slow, because the overall operation outcome and latency aren't impacted by the outlier. This is a big deal: A write can be successful and fast even when something is broken.
The simple 2/3 quorum would allow you to tolerate a loss of an entire Availability Zone. This is still not good enough, though. While a loss of a zone is a rare event, it doesn't make component failures in other zones any less likely. With Aurora, our goal is Availability Zone+1: we want to be able to tolerate a loss of a zone plus one more failure without any data durability loss, and with a minimal impact on data availability. We use a 4/6 quorum to achieve this:
For each logical log write, we issue six physical replica writes, and consider the write operation to be successful when four of those writes complete. With two replicas per zone, if an entire Availability Zone goes down, a write is still going to complete. If a zone goes down and an additional failure occurs, you can still achieve read quorum, and then quickly regain the ability to write by doing a fast repair.
Fast repairs and catchup
There are different ways to do data replication. In traditional storage systems, data mirroring or erasure coding occurs at the level of an entire physical storage unit, with several units combined together in a RAID array. This approach makes repairs slow. RAID array rebuild performance is limited by the capabilities of the small number of devices in the array. As storage devices get larger, so does the amount of data that should be copied during a rebuild.
Amazon Aurora uses an entirely different approach to replication, based on sharding and scale-out architecture. An Aurora database volume is logically divided into 10-GiB logical units (protection groups), and each protection group is replicated six ways into physical units (segments). Individual segments are spread across a large distributed storage fleet. When a failure occurs and takes out a segment, the repair of a single protection group only requires moving ~10 GiB of data, which is done in seconds.
Moreover, when multiple protection groups must be repaired, the entire storage fleet participates in the repair process. That offers massive bandwidth to complete the entire batch of repairs quickly. So, in the event of a zone loss followed by another component failure, Aurora may lose write quorum for a few seconds for a given protection group. However, an automatically initiated repair then restores writability with great speed. In other words, Aurora Storage quickly heals itself.
How is it possible to replicate data six ways and maintain high performance of writes? This would not be possible in a traditional database architecture, where full pages or disk sectors are written to storage, as the network would be swamped. By contrast, with Aurora, instances only write redo log records to storage. Those records are much smaller (typically tens to hundreds of bytes), and this makes a 4/6 write quorum possible without overloading the network.
The basic idea of a write quorum implies that some segments may not initially receive all of the writes, all of the time. How do those segments deal with gaps in the redo log stream? Aurora storage nodes continuously "gossip" among themselves to fill holes (and perform repairs). Log stream advancement is tightly orchestrated through Log Sequence Number (LSN) management. We use a set of LSN markers to maintain the state of each individual segment.
What about reads? A quorum read is expensive, and is best avoided. The client-side Aurora storage driver tracks which writes were successful for which segments. It does not need to perform a quorum read on routine page reads, because it always knows where to obtain an up-to-date copy of a page. Furthermore, the driver tracks read latencies, and always tries to read from the storage node that has demonstrated the lowest latency in the past. The only scenario when a quorum read is needed is during recovery on a database instance restart. The initial set of LSN markers must be reconstructed by asking storage nodes.
Foundation for innovation
Many remarkable new Aurora features are directly enabled by the distributed, self-healing storage architecture. To name a few:
- Read scalability: In addition to the master database instance, up to 15 read replicas can be provisioned across multiple zones in Aurora, for read scalability and higher availability. Read replicas use the same shared storage volume as the master.
- Continuous backup and point-in-time restore: The Aurora storage layer continuously and transparently backs up redo log streams to Amazon S3. You can perform a point-in-time-restore to any timestamp within the configured backup window. There is no need to schedule snapshot creation, and no transactions are lost when the snapshot closest to the time of interest is farther away.
- Fast clone: The Aurora storage layer can rapidly create a physical copy of a volume without needing to copy all the pages. Pages are initially shared between parent and child volumes, with copy-on-write completed when pages are modified. There is no duplicate cost when a volume is cloned.
- Backtrack: A quick way to bring the database to a particular point in time without having to do a full restore from a backup. Dropped a table by mistake? You can turn back time with Aurora backtracking.
There are many more relational database innovations to come, built on the foundation of the Aurora storage engine. We've all entered a new era of the relational database, and Aurora is just the beginning. The customer response has been one of resounding agreement. Leaders in every industry—like Capital One, Dow Jones, Netflix, and Verizon—are migrating their relational database workloads to Aurora, including MySQL and PostgreSQL-compatible editions.
Want to learn more about Amazon Aurora design?
Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. In SIGMOD 2017
Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes. In SIGMOD 2018