Amazon Redshift and the art of performance optimization in the cloud

People often ask me if developing for the cloud is any different from developing on-premises software. It really is. In this post, I show some of the reasons why that's true, using the Amazon Redshift team and the approach they have taken to improve the performance of their data warehousing service as an example. The Amazon Redshift team has delivered remarkable gains using a few simple engineering techniques:
- Leveraging fleet telemetry
- Verifying benchmark claims
- Optimizing performance for bursts of user activity
Leveraging fleet telemetry
The biggest difference between developing for the cloud and developing on-premises software is that in the cloud, you have much better access to how your customers are using your services.
Every week, the Amazon Redshift team performs a scan of their fleet and generates a Jupyter notebook showing an aggregate view of customer workloads. They don't collect the specific queries, just generic information such as the operation, count, duration, and plan shape. This yields hundreds of millions of data samples. I picked a few graphs to demonstrate, showing frequency, duration, and query plan for both SELECT and INSERT/UPDATE/DELETE statements.
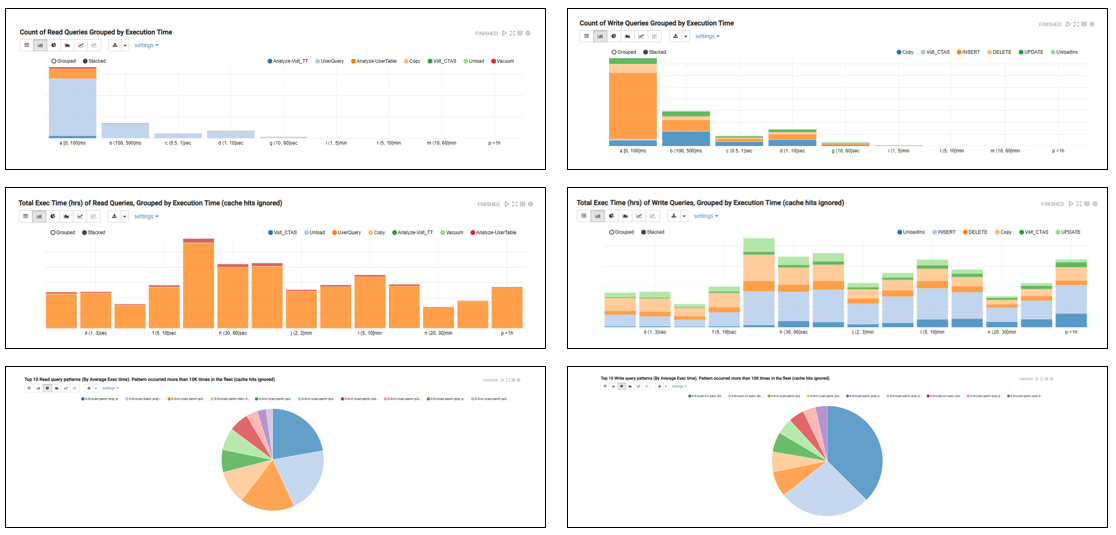
Looking at the graphs, you can see that customers run almost as many INSERT/UPDATE/DELETE statements on their Amazon Redshift data warehouses as they do SELECT. Clearly, they're updating their systems far more frequently than they did on-premises, which changes the nature of engineering problems the team needs to prioritize.
You can also see that runtime roughly follows a power law distribution—even though the vast majority of queries run in under 100 ms, the aggregate time in each bucket is about the same. Each week, the team's job is to find something that shifts the durations left and aggregate time down by looking at query shapes to find the largest opportunities for improvement.
Doing so has yielded impressive results over the past year. On a fleet-wide basis, repetitive queries are 17x faster, deletes are 10x faster, single-row inserts are 3x faster, and commits are 2x faster. I picked these examples because they aren't operations that show up in standard data warehousing benchmarks, yet are meaningful parts of customer workloads.
These sorts of gains aren't magic—just disciplined engineering incrementally improving performance by 5-10% with each patch. Over just the past 6 months, these gains have resulted in a 3.5x increase in Amazon Redshift's query throughput. So, small improvements add up. The key is knowing what to improve.
Verifying benchmark claims
I believe that making iterative improvements based on trends observed from fleet telemetry data is the best way to improve customer experience. That said, it is important to monitor benchmarks that help customers compare one cloud data warehousing vendor to another.
I've noticed a troubling trend in vendor benchmarking claims over the past year. Below, I show measurements on comparable hardware for Amazon Redshift and three other vendors who have been recently claiming order-of-magnitude better performance and pricing. As you see later, the reality is different from their claims. Amazon Redshift is up to 16 times faster and up to eight times cheaper than the other vendors.

It is important, when providing performance data, to use queries derived from industry standard benchmarks such as TPC-DS, not synthetic workloads skewed to show cherry-picked queries. It is important to show both, cases where you're better as well as ones where you're behind.
And, it is important to provide the specific setup so customers can replicate the numbers for themselves. The code and scripts used by the Amazon Redshift team for benchmarking are available on GitHub and the accompanying dataset is hosted in a public Amazon S3 bucket. The scientific method requires results to be reproducible—in the cloud, it should be straightforward for customers to do so.
Note: You need valid AWS credentials to access the public S3 data. Script users should update the DDL file with their own AWS keys to load the TPC-DS data.
Optimizing performance for bursts of user activity
Another significant difference between on-premises systems and the cloud is the abundance of available resources. A typical data warehouse has significant variance in concurrent query usage over the course of a day. It is more cost-effective to add resources just for the period during which they are required rather than provisioning to peak demand.
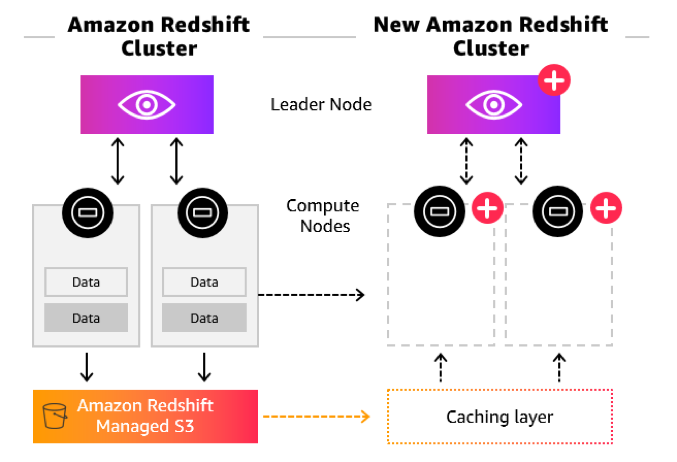
Concurrency Scaling is a new feature in Amazon Redshift that adds transient capacity when needed, to handle heavy demand from concurrent users and queries. Due to the performance improvements discussed above, 87% of current customers don't have any significant queue wait times and don't need concurrency beyond what their main cluster provides. The remaining 13% have bursts in concurrent demand, averaging 10 minutes at a time.
With the new feature, Amazon Redshift automatically spins up a cluster for the period during which increased concurrency causes queries to wait in the queue. For every 24 hours that your main cluster is in use, you accrue a one-hour credit for Concurrency Scaling. These means that Concurrency Scaling is free for more than 97% of customers.
For any usage that exceeds accrued credits at the end of the month, customers are billed on a per-second basis. This ensures that customers not only get consistently fast performance, but also predictable month-to-month costs, even during periods of high demand variability. In the following diagram, see how the throughput of queries derived from the TPC-H benchmark goes up as the number of concurrent users increase and Amazon Redshift adds transient clusters.
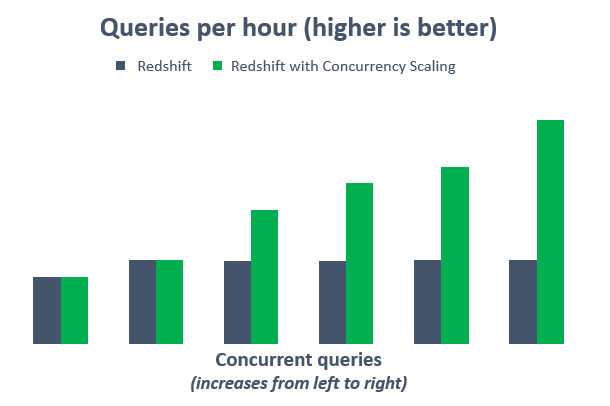
Concurrency Scaling is a good example of how the Amazon Redshift team is able to leverage the elasticity of cloud resources to automatically scale capacity as needed. For Amazon Redshift customers, this results in consistently fast performance for all users and workloads, even with thousands of concurrent queries.
Conclusion
Concurrency Scaling is launching soon. You can sign up for the preview to receive an email notification when the feature is available for you to try. I hope to see you at re:Invent 2018, where you can hear more about Amazon Redshift's performance optimization techniques and how they are helping AWS customers reduce their analysts' time-to-insight.