A one size fits all database doesn't fit anyone
A common question that I get is why do we offer so many database products? The answer for me is simple: Developers want their applications to be well architected and scale effectively. To do this, they need to be able to use multiple databases and data models within the same application.
Seldom can one database fit the needs of multiple distinct use cases. The days of the one-size-fits-all monolithic database are behind us, and developers are now building highly distributed applications using a multitude of purpose-built databases. Developers are doing what they do best: breaking complex applications into smaller pieces and then picking the best tool to solve each problem. The best tool for a job usually differs by use case.
For decades because the only database choice was a relational database, no matter the shape or function of the data in the application, the data was modeled as relational. Instead of the use case driving the requirements for the database, it was the other way around. The database was driving the data model for the application use case. Is a relational database purpose-built for a normalized schema and to enforce referential integrity in the database? Absolutely, but the key point here is that not all application data models or use cases match the relational model.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. We found that about 70 percent of our operations were key-value lookups, where only a primary key was used and a single row would be returned. With no need for referential integrity and transactions, we realized these access patterns could be better served by a different type of database. Further, with the growth and scale of Amazon.com, boundless horizontal scale needed to be a key design point–scaling up simply wasn't an option. This, ultimately led to DynamoDB, a nonrelational database service built to scale out beyond the limits of relational databases.
This doesn't mean relational databases do not provide utility in present-day development and are not available, scalable, or provide high performance. The opposite is true. In fact, this is been proven by our customers as Amazon Aurora remains the fastest growing service in AWS history. What we experienced at Amazon.com was using a database beyond its intended purpose. That learning is at the heart of this blog post—databases are built for a purpose and matching the use case with the database will help you write high-performance, scalable, and more functional applications faster.
Purpose-built databases
The world is still changing and the categories of nonrelational databases continue to grow. We are increasingly seeing customers wanting to build Internet-scale applications that require diverse data models. In response to these needs, developers now have the choice of relational, key-value, document, graph, in-memory, and search databases. Each of these databases solve a specific problem or a group of problems.
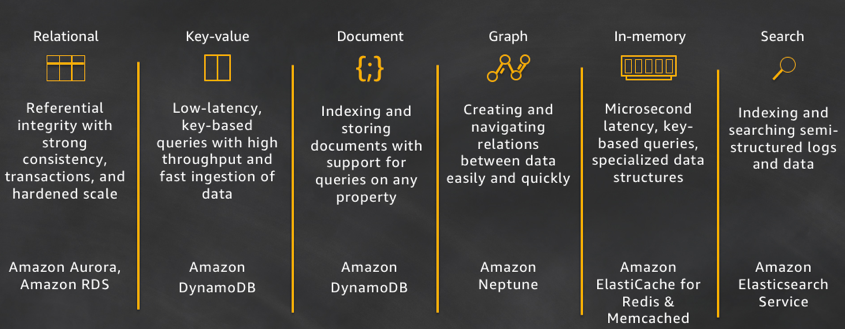
Let's take a closer look at the purpose for each of these databases:
Relational: A relational database is self-describing because it enables developers to define the database's schema as well as relations and constraints between rows and tables in the database. Developers rely on the functionality of the relational database (not the application code) to enforce the schema and preserve the referential integrity of the data within the database. Typical use cases for a relational database include web and mobile applications, enterprise applications, and online gaming. Airbnb is a great example of a customer building high-performance and scalable applications with Amazon Aurora. Aurora provides Airbnb a fully-managed, scalable, and functional service to run their MySQL workloads.
Key-value: Key-value databases are highly partitionable and allow horizontal scaling at levels that other types of databases cannot achieve. Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads. This consistent performance is a big part of why the Snapchat Stories feature, which includes Snapchat's largest storage write workload, moved to DynamoDB.
Document: Document databases are intuitive for developers to use because the data in the application tier is typically represented as a JSON document. Developers can persist data using the same document model format that they use in their application code. Tinder is one example of a customer that is using the flexible schema model of DynamoDB to achieve developer efficiency.
Graph: A graph database's purpose is to make it easy to build and run applications that work with highly connected datasets. Typical use cases for a graph database include social networking, recommendation engines, fraud detection, and knowledge graphs. Amazon Neptune is a fully-managed graph database service. Neptune supports both the Property Graph model and the Resource Description Framework (RDF), giving you the choice of two graph APIs: TinkerPop and RDF/SPARQL. Current Neptune users are building knowledge graphs, making in-game offer recommendations, and detecting fraud. For example, Thomson Reuters is helping their customers navigate a complex web of global tax policies and regulations by using Neptune.
In-memory: Financial services, Ecommerce, web, and mobile application have use cases such as leaderboards, session stores, and real-time analytics that require microsecond response times and can have large spikes in traffic coming at any time. We built Amazon ElastiCache, offering Memcached and Redis, to serve low latency, high throughput workloads, such as McDonald's, that cannot be served with disk-based data stores. Amazon DynamoDB Accelerator (DAX) is another example of a purpose-built data store. DAX was built is to make DynamoDB reads an order of magnitude faster.
Search: Many applications output logs to help developers troubleshoot issues. Amazon Elasticsearch Service (Amazon ES) is purpose built for providing near real-time visualizations and analytics of machine-generated data by indexing, aggregating, and searching semi structured logs and metrics. Amazon ES is also a powerful, high-performance search engine for full-text search use cases. Expedia is using more than 150 Amazon ES domains, 30 TB of data, and 30 billion documents for a variety of mission-critical use cases, ranging from operational monitoring and troubleshooting to distributed application stack tracing and pricing optimization.
Building applications with purpose-built databases
Developers are building highly distributed and decoupled applications, and AWS enables developers to build these cloud-native applications by using multiple AWS services. Take Expedia, for example. Though to a customer the Expedia website looks like a single application, behind the scenes Expedia.com is composed of many components, each with a specific function. By breaking an application such as Expedia.com into multiple components that have specific jobs (such as microservices, containers, and AWS Lambda functions), developers can be more productive by increasing scale and performance, reducing operations, increasing deployment agility, and enabling different components to evolve independently. When building applications, developers can pair each use case with the database that best suits the need.
To make this real, take a look at some of our customers that are using multiple different kinds of databases to build their applications:
- Airbnb uses DynamoDB to store users' search history for quick lookups as part of personalized search. Airbnb also uses ElastiCache to store session states in-memory for faster site rendering, and they use MySQL on Amazon RDS as their primary transactional database.
- Capital One uses Amazon RDS to store transaction data for state management, Amazon Redshift to store web logs for analytics that need aggregations, and DynamoDB to store user data so that customers can quickly access their information with the Capital One app.
- Expedia built a real-time data warehouse for the market pricing of lodging and availability data for internal market analysis by using Aurora, Amazon Redshift, and ElastiCache. The data warehouse performs a multistream union and self-join with a 24-hour lookback window using ElastiCache for Redis. The data warehouse also persists the processed data directly into Aurora MySQL and Amazon Redshift to support both operational and analytical queries.
- Zynga migrated the Zynga poker database from a MySQL farm to DynamoDB and got a massive performance boost. Queries that used to take 30 seconds now take one second. Zynga also uses ElastiCache (Memcached and Redis) in place of their self-managed equivalents for in-memory caching. The automation and serverless scalability of Aurora make it Zynga's first choice for new services using relational databases.
- Johnson & Johnson uses Amazon RDS, DynamoDB, and Amazon Redshift to minimize time and effort spent on gathering and provisioning data, and allow the quick derivation of insights. AWS database services are helping Johnson & Johnson improve physicians' workflows, optimize the supply chain, and discover new drugs.
Just as they are no longer writing monolithic applications, developers also are no longer using a single database for all use cases in an application—they are using many databases. Though the relational database remains alive and well, and is still well suited for many use cases, purpose-built databases for key-value, document, graph, in-memory, and search uses cases can help you optimize for functionality, performance, and scale and—more importantly—your customers' experience. Build on.