Looking back at 10 years of compartmentalization at AWS
At AWS, we don't mark many anniversaries. But every year when March 14th comes around, it's a good reminder that Amazon S3 originally launched on Pi Day, March 14, 2006. The Amazon S3 team still celebrate with homemade pies!
March 26, 2008 doesn't have any delicious desserts associated with it, but that's the day when we launched Availability Zones for Amazon EC2. A concept that has changed infrastructure architecture is now at the core of both AWS and customer reliability and operations.
Powering the virtual instances and other resources that make up the AWS Cloud are real physical data centers with AWS servers in them. Each data center is highly reliable, and has redundant power, including UPS and generators. Even though the network design for each data center is massively redundant, interruptions can still occur.
Availability Zones draw a hard line around the scope and magnitude of those interruptions. No two zones are allowed to share low-level core dependencies, such as power supply or a core network. Different zones can't even be in the same building, although sometimes they are large enough that a single zone spans several buildings.
We launched with three autonomous Availability Zones in our US East (N. Virginia) Region. By using zones, and failover mechanisms such as Elastic IP addresses and Elastic Load Balancing, you can provision your infrastructure with redundancy in mind. When two instances are in different zones, and one suffers from a low-level interruption, the other instance should be unaffected.
How Availability Zones have changed over the years
Availability Zones were originally designed for physical redundancy, but over time they have become re-used for more and more purposes. Zones impact how we build, deploy, and operate software, as well as how we enforce security controls between our largest systems.
For example, many AWS services are now built so that as much functionality as possible can be autonomous within an Availability Zone. The calls used to launch and manage EC2 instances, fail over an RDS instance, or handle the health of instances behind a load balancer, all work within one zone.
This design has a double benefit. First, if an Availability Zone does lose power or connectivity, the remaining zones are unaffected. The second benefit is even more powerful: if there is an error in the software, the risk of that error affecting other zones is minimized.
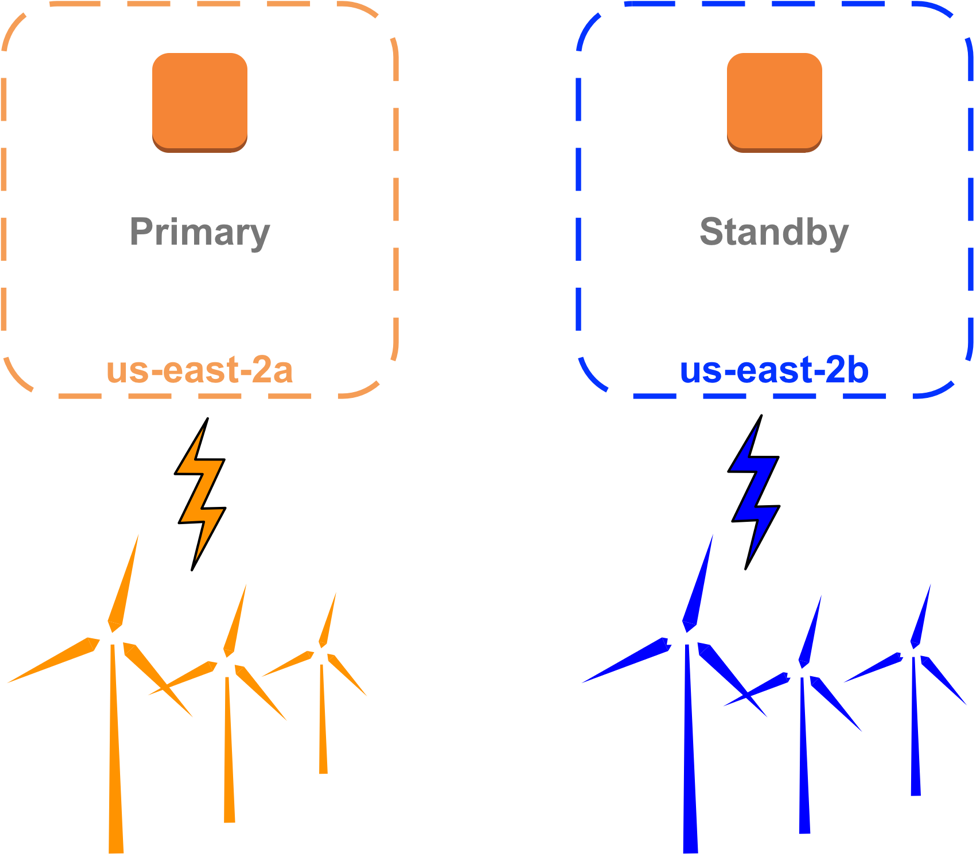
We maximize this benefit when we deploy new versions of our software, or operational changes such as a configuration edit, as we often do so zone-by-zone, one zone in a Region at a time. Although we automate, and don't manage instances by hand, our developers and operators know not to build tools or procedures that could impact multiple Availability Zones. I'd wager that every new AWS engineer knows within their first week, if not their first day, that we never want to touch more than one zone at a time.
Availability Zones run deep in our AWS development and operations culture, at every level. AWS customers can think of zones in terms of redundancy, "Use two or more Availability Zones for reliability." At AWS, we think of zones in terms of isolation, "Stay within the Availability Zone, as much as possible."
Silo your traffic or not – you choose
When your architecture does stay within an Availability Zone as much as possible, there are more benefits. One is that the latency within a zone is incredibly fast. Today, packets between EC2 instances in the same zone take just tens of microseconds to reach other.
Another benefit is that redundant zonal architectures are easier to recover from complex issues and emergent behaviors. If all of the calls between the various layers of a service stay within one Availability Zone, then when issues occur they can quickly be remediated by removing the entire zone from service, without needing to identify the layer or component that was the trigger.
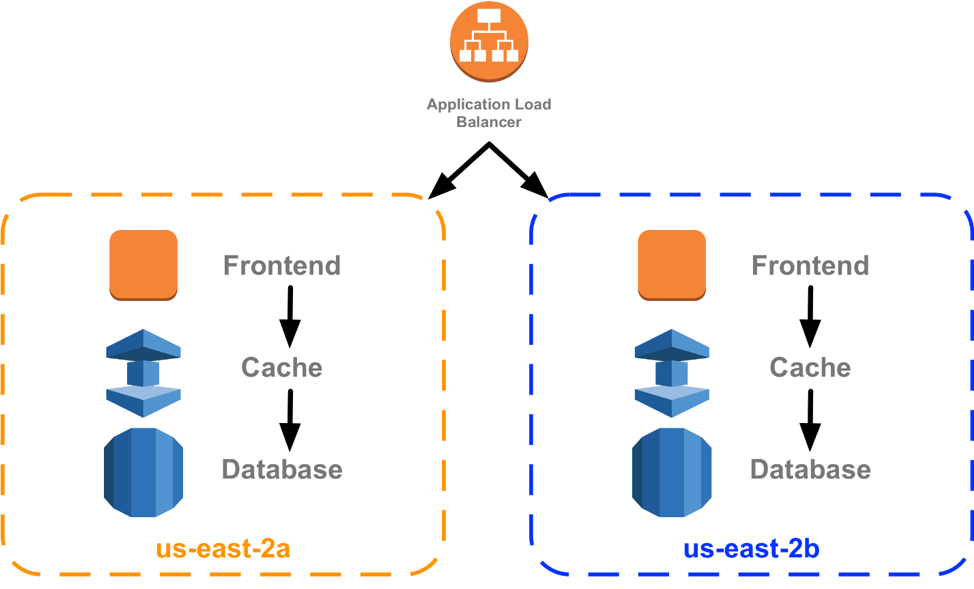
Many of you also use this kind of "silo" pattern in your own architecture, where Amazon Route 53 or Elastic Load Balancing can be used to choose an Availability Zone to handle a request, but can also be used to keep subsequent internal requests and dependencies within that same zone. This is only meaningful because of the strong boundaries and separation between zones at the AWS level.
Regional isolation
Not too long after we launched Availability Zones, we also launched our second Region, EU (Ireland). Early in the design, we considered operating a seamless global network, with open connectivity between instances in each Region. Services such as S3 would have behaved as "one big S3," with keys and data accessible and mutable from either location.
The more we thought through this design, the more we realized that there would be risks of issues and errors spreading between Regions, potentially resulting in large-scale interruptions that would defeat our most important goals:
- To provide the highest levels of availability
- To allow Regions to act as standby sites for each other
- To provide geographic diversity and lower latencies to end users
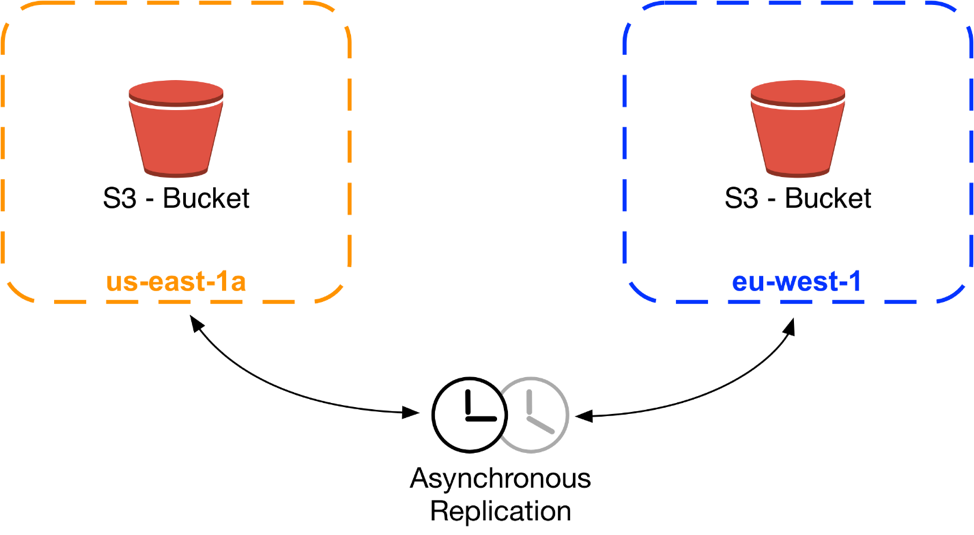
Our experience with the benefits of Availability Zones meant that instead we doubled down on compartmentalization, and decided to isolate Regions from each other with our hardest boundaries. Since then, and still today, our services operate autonomously in each Region, full stacks of S3, DynamoDB, Amazon RDS, and everything else.
Many of you still want to be able to run workloads and access data globally. For our edge services such as Amazon CloudFront, Amazon Route 53, and AWS Lambda@Edge, we operate over 100 points of presence. Each is its own Availability Zone with its own compartmentalization.
As we develop and ship our services that span Regions, such as S3 cross-region object replication, Amazon DynamoDB global tables, and Amazon VPC inter-region peering, we take enormous care to ensure that the dependencies and calling patterns between Regions are asynchronous and ring-fenced with high-level safety mechanisms that prevent errors from spreading.
Doubling down on compartmentalization, again
With the phenomenal growth of AWS, it can be humbling how many customers are being served even by our smallest Availability Zones. For some time now, many of our services have been operating service stacks that are compartmentalized even within zones.
For example, AWS HyperPlane—the internal service that powers NAT gateways, Network Load Balancers, and AWS PrivateLink—is internally subdivided into cells that each handle a distinct set of customers. If there are any issues with a cell, the impact is limited not just to an Availability Zone, but to a subset of customers within that zone. Of course, all sorts of automation immediately kick in to mitigate any impact to even that subset.
Ten years after launching Availability Zones, we're excited that we're still relentless about reducing the impact of potential issues. We firmly believe it's one of the most important strategies for achieving our top goals of security and availability. We now have 54 Availability Zones, across 18 geographic Regions, and we've announced plans for 12 more. Beyond that geographic growth, we'll be extending the concept of compartmentalization that underlies Availability Zones deeper and deeper, to be more effective than ever.