Back-to-Basics Weekend Reading - Bloom Filters
Listening to the “Algorithms to Live By” audio on my commute this morning, once again I was struck by the beauty of Bloom Filters. So, I decided it is time to resurrect the ‘Back-to-Basics Weekend Reading’ series, as I will be re-reading some fundamental CS papers this weekend.
In the past, I have done some weekend reading about Counting Bloom Filters, but now I am going even more fundamental, and I invite you to join me.
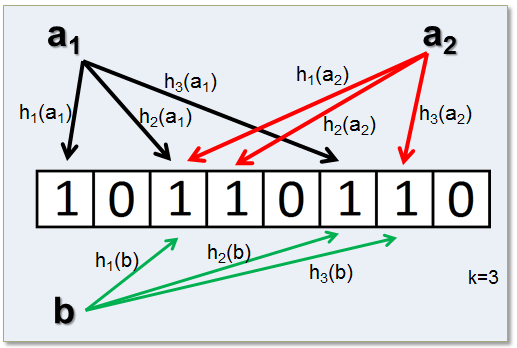
Bloom Filters, conceived by Burton Bloom in 1970, are probabilistic data structures to test whether an item is in a set. False positives are possible, but false negatives are not. Meaning, if a bit in the filter is not set, you can be sure the item is not in the set. If it is in the set, the mapped item may be in the set.
This is a hugely important technique if you need to process and track massive amounts of unique data units, as it is very space-efficient. From Dynamo and Postgresql, to HBase and Bitcoin, Bloom Filters are used in almost all modern distributed systems. This weekend I will be reading the original paper by Bloom from 1970, and another more recent survey paper that describes several variants and applications that have been developed over the years.
“Space/Time Trade-offs in Hash Coding with Allowable Errors”, Bloom, Burton H., in Communications of the ACM, 13 (7): 422–426
“Cache-, Hash- and Space-Efficient Bloom Filters”, Putze, F.; Sanders, P.; Singler, J., in Demetrescu, Camil, Experimental Algorithms, 6th International Workshop, WEA 200