Expanding the Cloud: Introducing Amazon QuickSight
We live in a world where massive volumes of data are being generated from websites, connected devices and mobile apps. In such a data intensive environment, making key business decisions such as running marketing and sales campaigns, logistic planning, financial analysis, and ad targeting require deriving insights from these data. However, the data infrastructure to collect, store, and process data is geared primarily towards developers and IT professionals (e.g., Amazon Redshift, Amazon DynamoDB, Amazon EMR) whereas insights need to be derived by not just technical professionals but also non-technical, business users.
In our quest to enable the best data storage options for customers, over the years we have built several innovative database solutions such as Amazon RDS, Amazon RDS for Aurora, Amazon DynamoDB, and Amazon Redshift. Not surprisingly, customers are using them to collect and store massive amounts of data. Yet, the process of deriving actionable insights out of this wide variety of data sources is not easy. Traditionally, companies had to invest in a lot of complex tools to discover their data sets, ETL tools to prepare for analysis, and separate tools for analyzing and providing visually interactive dashboards.
Today, I am excited to share with you a brand new service called Amazon QuickSight that aims to simplify the process of deriving insights from a wide variety of data sources quickly, easily and at a low cost. QuickSight is a very fast, cloud powered, business intelligence service for the 1/10th the cost of old-guard BI solutions.
Big data challenges
Over the last several years, AWS has delivered on a comprehensive set of services to help customers collect, store, and process their growing volume of data. Today, many thousands of companies—from large enterprises such as Johnson & Johnson, Samsung, and Philips to established technology companies such as Netflix and Adobe to innovative startups such as Airbnb, Yelp, and Foursquare—use Amazon Web Services for their big data needs.
Every day, large amount of data is generated from customer applications running on top of AWS infrastructure, collected and streamed using services like Amazon Kinesis, and stored in AWS relational data sources such as Amazon RDS, Amazon Aurora, and Amazon Redshift; NoSQL data sources such as Amazon DynamoDB; and file-based data sources such as Amazon S3. Customers also use a variety of different tools, including Amazon EMR for Hadoop, Amazon Machine Learning, AWS Data Pipeline, and AWS Lambda to process and analyze their data.
There’s an inherent gap between the data that is collected, stored, and processed and the key decisions that business users make on a daily basis. Put simply, data is not always readily available and accessible to organizational end users. Most business users continue to struggle answering key business questions such as “Who are my top customers and what are they buying?”, “How is my marketing campaign performing?”, and “Why is my most profitable region not growing?” While BI solutions have existed for decades, customers have told us that it takes an enormous amount of time, IT effort, and money to bridge this gap.
Traditional BI solutions typically require teams of data engineers to spend several months building complex data models and synthesizing the data before they can generate their first report. These solutions lack interactive data exploration and visualization capabilities, limiting most business users to canned reports and pre-selected queries.
On-premise BI tools also require companies to provision and maintain complex hardware infrastructure and invest in expensive software licenses, maintenance fees, and support fees that cost upwards of thousands of dollars per user per year. To scale to a larger number of users and support the growth in data volume spurred by social media, web, mobile, IoT, ad-tech, and ecommerce workloads, these tools require customers to invest in even more infrastructure to maintain a reasonable query performance. This cost and complexity to implement and scale BI makes it difficult for most companies to make BI ubiquitous across their organizations.
Enter Amazon QuickSight
QuickSight is a cloud powered BI service built from the ground up to address the big data challenges around speed, complexity, and cost. QuickSight puts data scattered across various different big data sources such as relational data sources, NoSQL data sources, and streaming data sets at the fingertips of your business users in an easy-to-use user interface and at one-tenth the cost of traditional BI solutions. Getting started with QuickSight is straightforward. Let me walk you through some of the core experiences of QuickSight that makes it so easy to set up, connect to your data sources, and build visualizations in minutes.
QuickSight is built on large number of innovative technologies to get a business user their first insights fast. Here are the few key innovations that power QuickSight:
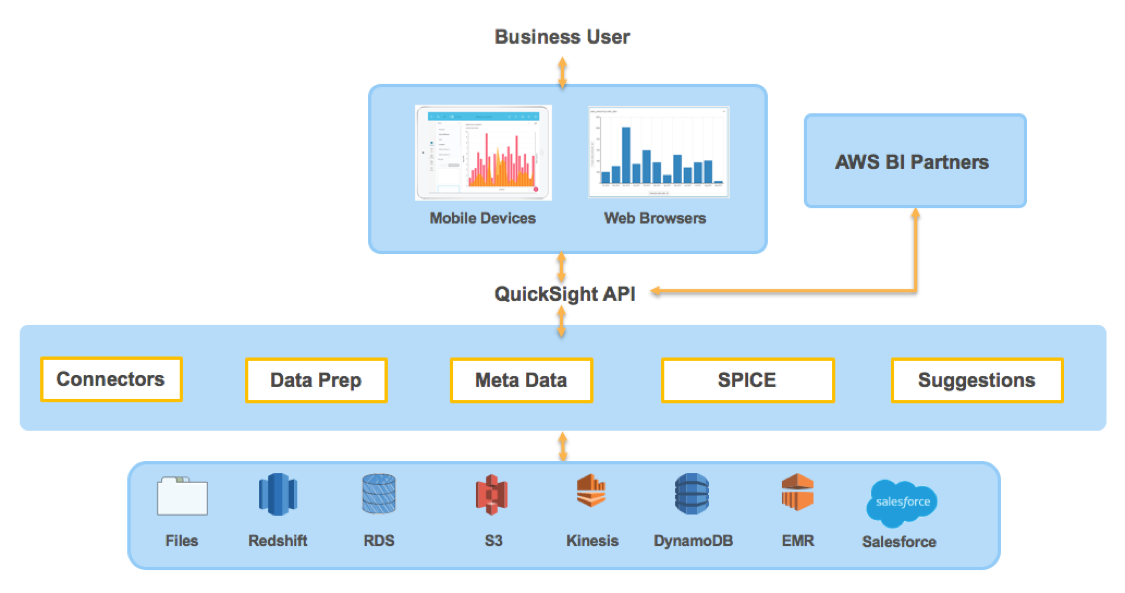
SPICE: One of the key ingredients that make QuickSight so powerful is the Super-fast, Parallel, In-memory Calculation Engine (SPICE). SPICE is a new technology built from the ground up by the same team that has also built technologies such as DynamoDB, Amazon Redshift, and Amazon Aurora. SPICE enables QuickSight to scale to many terabytes of analytical data and deliver response time for most visualization queries in milliseconds. When you point QuickSight to a data source, data is automatically ingested into SPICE for optimal analytical query performance. SPICE uses a combination of columnar storage, in-memory technologies enabled through the latest hardware innovations, machine code generation, and data compression to allow users to run interactive queries on large datasets and get rapid responses. SPICE supports rich calculations that help customers derive valuable insights as they explore their data without having to worry about provisioning or managing infrastructure. SPICE automatically replicates data for high availability and performance. This allows us to enable organizations to scale to thousands of users who can all perform fast, interactive analysis across a wide variety of AWS data sources. In addition to powering QuickSight, we are also enabling our AWS BI partners to integrate with SPICE, so that customers who use our partner tools can visualize their data quickly with a user interface that they are already familiar with.
Auto discovery: One of the challenges with BI and analytics is discovering the data and curating it for analytics. This requires an IT department to build a data catalog and make it discoverable with an analytics engine and tools. When a user logs in to QuickSight, it automatically discovers the list of data sources that a customer has access to and analyzes them without database configuration, setup, and so on. For instance, customers can visualize their data on an Amazon Redshift cluster by picking a table and then get to a visualization in less than 3 clicks. To enable this, we have built a live metadata catalog service that builds a catalog of data sources (e.g., Amazon Redshift, RDS, S3, Amazon EMR, and DynamoDB) to which the customer has access.
AutoGraph: Picking the right visualization is not easy, and there is lot of science behind it. For instance, optimal visualization depends on various factors: the type of data field one has selected (e.g., “Is it time, number, or string?”), cardinality of the data (e.g., “Does this field have only 4 unique values or 1 million values?”), and number of data fields one is trying to visualize. While QuickSight supports multiple graph types (e.g., bar charts, line graphs, scatter plots, box plots, pie charts, and so on), one of the things we have tried to simplify is a capability that automatically picks the right visualization for selected data using a technology called AutoGraph. With this, users pick which data fields they want to visualize and QuickSight automatically selects the right visual type for them.
Suggestions: Often the sheer volume of data can be overwhelming; many users just want to explore their data to learn interesting characteristics. For example, the most common query for sales data in an Amazon Redshift cluster might be “How do overall sales grow over time across different categories?” With QuickSight, we have built an engine that provides suggestions for interesting analytics that users might be interested in when they pick a data source to analyze. The engine derives its suggestions by analyzing the metadata of the data source, its most accessed queries and several other parameters. We believe this provides a simple way for users to deriving valuable insights without too much work.
Collaboration and sharing of live analytics: Often users want to slice and dice their data and share their analysis in a secure manner. With QuickSight, users can build a “storyboard” that contains multiple analyses with appropriate annotations, and share it with others in their organization. Unlike traditional tools, they can share live analysis instead of static images so that recipients can also derive insights on the storyboard that was shared. For enterprises, we are also providing Active Directory integration so that customers can share insights using their existing credentials.
I have highlighted only some of the key innovations behind QuickSight in this post. For detailed information about this product, visit the AWS Blog, the QuickSight Detail Page and the FAQ page.
What our customers are saying about QuickSight
As I mentioned earlier, many innovations at Amazon and AWS, including QuickSight, are driven by customer feedback. We actively listen to your pain points and handle the undifferentiated heavy lifting across the various dimensions of infrastructure, data management, and analytics. This strategy of constantly listening to customer feedback, and iterating on our capabilities rapidly, has been a virtuous cycle that has consistently worked well for us. QuickSight also started with similar roots and during the final stages of launch, I am pleased to hear such positive feedback from customers. We have heard great excitement from our customers like Nasdaq, and Intuit.
Nasdaq enables their customers to plan, optimize, and execute their business vision with confidence, using proven technologies to provide transparency and insight for navigating today’s global capital markets. Their technology powers more than 100 marketplaces, clearinghouses, and central securities depositories in 50 countries, and so generates a lot of data. Nate Simmons, Principal Architect of Nasdaq Inc., tells us that they are always interested in new tools to analyze the data we have stored in Amazon Redshift, Amazon S3, and other sources. For him, having super-fast performance as the data volumes and usage grows is critical to their users. Based on their preview of QuickSight, they found the SPICE in-memory calculation engine combined with an easy-to-use UI to be appealing for their use cases.
Similarly, Troy Otillio, Director of Public Cloud at Intuit, tells us that based on their initial preview of QuickSight, they think this service is going to challenge the status quo. He mentions that it appears to be intuitive for their business users, particular those in marketing who need an easy-to-user tool with super-fast performance.
Summing it all up
We are excited about the launch of Amazon QuickSight and its early feedback. We believe this is one of the critical parts of our big data offerings. If you are interested in trying the product during our preview, you can sign up for the preview today.