Taking DynamoDB beyond Key-Value: Now with Faster, More Flexible, More Powerful Query Capabilities
We launched DynamoDB last year to address the need for a cloud database that provides seamless scalability, irrespective of whether you are doing ten transactions or ten million transactions, while providing rock solid durability and availability. Our vision from the day we conceived DynamoDB was to fulfil this need without limiting the query functionality that people have come to expect from a database. However, we also knew that building a distributed database that has unlimited scale and maintains predictably high performance while providing rich and flexible query capabilities, is one of the hardest problems in database development, and will take a lot of effort and invention from our team of distributed database engineers to solve. So when we launched in January 2012, we provided simple query functionality that used hash primary keys or composite primary keys (hash + range). Since then, we have been working on adding flexible querying. You saw the first iteration in April 2013 with the launch of Local Secondary Indexes (LSI). Today, I am thrilled to announce a fundamental expansion of the query capabilities of DynamoDB with the launch of Global Secondary Indexes (GSI). This new capability allows indexing any attribute (column) of a DynamoDB table and performing high-performance queries at any table scale.
Going beyond Key-Value
Advanced Key-value data stores such as DynamoDB achieve high scalability on loosely coupled clusters by using the primary key as the partitioning key to distribute data across nodes. Even though the resulting query functionality may appear more limiting than a relational database on a cursory examination, it works exceedingly well for a wide range of applications as evident from DynamoDB’s rapid growth and adoption by customers like Electronic Arts, Scopley, HasOffers, SmugMug, AdRoll, Dropcam, Digg and by many teams at Amazon.com (Cloud Drive, Retail). DynamoDB continues to be embraced for workloads in Gaming, Ad-tech, Mobile, Web Apps, and other segments where scale and performance are critical. At Amazon.com, we increasingly default to DynamoDB instead of using relational databases when we don’t need complex query, table join and transaction capabilities, as it offers a more available, more scalable and ultimately a lower cost solution.
For non-primary key access in advanced key-value stores, a user has to resort to either maintaining a separate table or some form of scatter-gather query across partitions. Both these options are less than ideal. For instance, maintaining a separate table for indexes forces users to maintain consistency between the primary key table and the index tables. On the other hand, with a scatter gather query, as the dataset grows, the query must be scattered more and more resulting in poor performance over time. DynamoDB’s new Global Secondary Indexes remove this fundamental restriction by allowing “scaled out” indexes without ever requiring any book-keeping on behalf of the developer. Now you can run queries on any item attributes (columns) in your DynamoDB table. Moreover, a GSI’s performance is designed to meet DynamoDB’s single digit millisecond latency - you can add items to a Users table for a gaming app with tens of millions of users with UserId as the primary key, but retrieve them based on their home city, with no reduction in query performance.
DynamoDB Refresher
DynamoDB stores information as database tables, which are collections of individual items. Each item is a collection of data attributes. The items are analogous to rows in a spreadsheet, and the attributes are analogous to columns. Each item is uniquely identified by a primary key, which is composed of its first two attributes, called the hash and range. DynamoDB queries refer to the hash and range attributes of items you’d like to access. These query capabilities so far have been based on the default primary index and optional local secondary indexes of a DynamoDB table:
- Primary Index: Customers can choose from two types of keys for primary index querying: Simple Hash Keys and Composite Hash Key / Range Keys. Simple Hash Key gives DynamoDB the Distributed Hash Table abstraction. The key is hashed over the different partitions to optimize workload distribution. For more background on this please read the original Dynamo paper. Composite Hash Key with Range Key allows the developer to create a primary key that is the composite of two attributes, a “hash attribute” and a “range attribute.” When querying against a composite key, the hash attribute needs to be uniquely matched but a range operation can be specified for the range attribute: e.g. all orders from Werner in the past 24 hours, or all games played by an individual player in the past 24 hours.
- Local Secondary Index: Local Secondary Indexes allow the developer to create indexes on non-primary key attributes and quickly retrieve records within a hash partition (i.e., items that share the same hash value in their primary key): e.g. if there is a DynamoDB table with PlayerName as the hash key and GameStartTime as the range key, you can use local secondary indexes to run efficient queries on other attributes like “Score.” Query “Show me John’s all-time top 5 scores” will return results automatically ordered by score.
What are Global Secondary Indexes?
Global secondary indexes allow you to efficiently query over the whole DynamoDB table, not just within a partition as local secondary indexes, using any attributes (columns), even as the DynamoDB table horizontally scales to accommodate your needs. Let’s walk through another gaming example. Consider a table named GameScores that keeps track of users and scores for a mobile gaming application. Each item in GameScores is identified by a hash key (UserId) and a range key (GameTitle). The following diagram shows how the items in the table would be organized. (Not all of the attributes are shown)
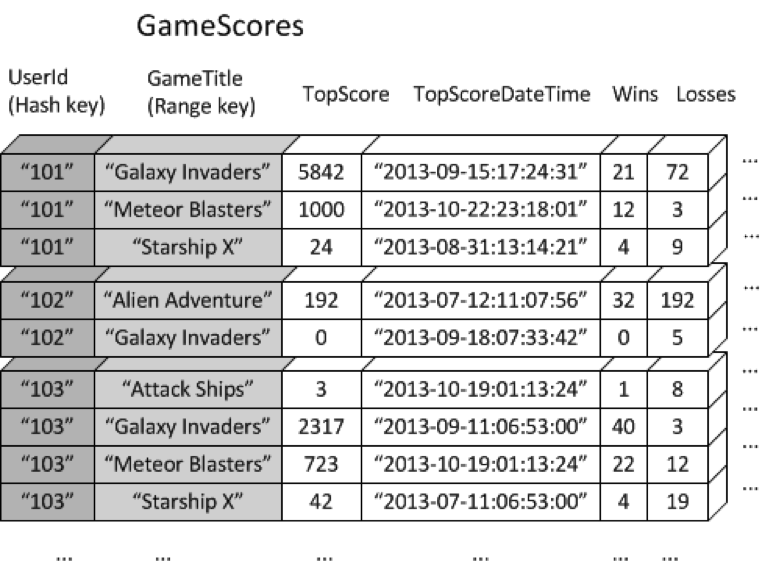
Now suppose that you wanted to write a leaderboard application to display top scores for each game. A query that specified the key attributes (UserId and GameTitle) would be very efficient; however, if the application needed to retrieve data from GameScores based on GameTitle only, it would need to use a Scan operation. As more items are added to the table, scans of all the data would become slow and inefficient, making it difficult to answer questions such as
- What is the top score ever recorded for the game “Meteor Blasters”?
- Which user had the highest score for “Galaxy Invaders”?
- What was the highest ratio of wins vs. losses?
To speed up queries on non-key attributes, you can specify global secondary indexes. For example, you could create a global secondary index named GameTitleIndex, with a hash key of GameTitle and a range key of TopScore. Since the table’s primary key attributes are always projected into an index, the UserId attribute is also present. The following diagram shows what GameTitleIndex index would look like:

Now you can query GameTitleIndex and easily obtain the scores for “Meteor Blasters”. The results are ordered by the range key, TopScore.
Efficient Queries
Traditionally, databases have been scaled as a whole –tables and indexes together. While this may appear simple, it masked the underlying complexity of varying needs for different types of queries and consequently different indexes, which resulted in wasted resources. With global secondary indexes in DynamoDB, you can now have many indexes and tune their capacity independently. These indexes also provide query/cost flexibility, allowing a custom level of clustering to be defined per index. Developers can specify which attributes should be “projected” to the secondary index, allowing faster access to often-accessed data, while avoiding extra read/write costs for other attributes.
Start with DynamoDB
The enhanced query flexibility that global and local secondary indexes provide means DynamoDB can support an even broader range of workloads. When designing a new application that will operate in the AWS cloud, first take a look at DynamoDB when selecting a database. If you don’t need the table join capabilities of relational databases, you will be better served from a cost, availability and performance standpoint by using DynamoDB. If you need support for transactions, use the recently released transaction library. You can also use GSI features with DynamoDB Local for offline development of your application. As your application becomes popular and goes from being used by thousands of users to millions or even tens of millions of users, you will not have to worry about the typical performance or availability bottlenecks applications face from relational databases that require application re-architecture. You can simply dial up the provisioned throughput that your app needs from DynamoDB and we will take care of the rest without any impact on the performance of your app.
Dropcam tells us that they adopted DynamoDB for seamless scalability and performance as they continue to innovate on their cloud based monitoring platform which has grown to become one of the largest video platforms on the internet today. With GSIs, they do not have to choose between scalability and query flexibility and instead can get both out of their database. Guerrilla Games, the developer of Killzone Shadow Fall uses DynamoDB for online multiplayer leaderboards and game settings. They will be leveraging GSIs to add more features and increase database performance. Also, Bizo, a B2B digital marketing platform, uses DynamoDB for audience targeting. GSIs will enable lookups using evolving criterion across multiple datasets.
These are just a few examples where GSIs can help and I am looking forward to our customers building scalable businesses with DynamoDB. I want application writers to focus on their business logic, leaving the heavy-lifting of maintaining consistency across look-up attributes to DynamoDB. To learn more see Jeff Barr’s blog and the DynamoDB developer guide.