Expanding the Cloud: Moving large data sets into Amazon S3 with AWS Import/Export.
Before networks were everywhere, the easiest way to transport information from one computer in your machine room was to write the data to a floppy disk, run to the computer and load the data there from that floppy. This form of data transport was jokingly called "sneaker net". It was efficient because networks only had limited bandwidth and you wanted to reserve that for essential tasks.
In some ways the computing world has changed dramatically; networks have become ubiquitous and the latency and bandwidth capabilities have improved immensely. Next to this growth in network capabilities we have been able to grow something else to even bigger proportions, namely our datasets. Gigabyte data sets are considered small, terabyte sets are common place, and we see several customers working with petabyte size datasets.
No matter how much we have improved our network throughput in the past 10 years, our datasets have grown faster, and this is likely to be a pattern that will only accelerate in the coming years. While network may improve another other of magnitude in throughput, it is certain that datasets will grow two or more orders of magnitude in the same period of time.
At the same time processing large amounts of data has become common place. Where this used to be the domain of Physics and Biotech researchers or maybe business intelligence, now increasingly other domains are being driven by large datasets. In research we see that traditional social sciences such as psychology and history are moving to become data driven. In the commercial world for example no ecommerce site can function anymore without mining massive amounts of data to optimize recommendations to their customers. Also in the systems management domain, data sets are growing faster and faster, consequently backup and disaster recovery has to deal with increasingly large sets. Log files and monitoring also spew out more and more relevant data.
Many of our customers have large datasets and would love to move into our storage services and process them in Amazon EC2. However moving these large datasets over the network can be cumbersome. If you look at typical network speeds and how long it would take to move a terabyte dataset:
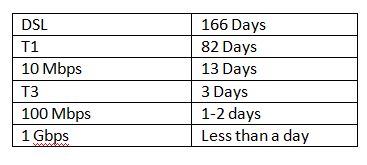
Depending on the network throughput available to you and the data set size it may take rather long to move your data into Amazon S3. To help customers move their large data sets into Amazon S3 faster, we offer them the ability to do this over Amazon's internal high-speed network using AWS Import/Export.
AWS Import/Export allows you to ship your data on one or more portable storage devices to be loaded into Amazon S3. For each portable storage device to be loaded, a manifest explains how and where to load the data, and how to map file to Amazon S3 object keys. After loading the data into Amazon S3, AWS Import/Export stores the resulting keys and MD5 Checksums in log files such that you can check whether the transfer was successful.
AWS Import/Export is of great help to many of our customers who have to handle large data sets. We continue to listen to our customers to make sure we are adding features, tools and services that help them solve real problems. For more information on AWS Import/Export visit the detail page.
For more background on the evolution of large data sets and the challenges with moving them over the network you should read some papers and interviews with Jim Gray who was a pioneer in the area of computing.