MXNet - Deep Learning Framework of Choice at AWS

Machine learning is playing an increasingly important role in many areas of our businesses and our lives and is being employed in a range of computing tasks where programming explicit algorithms is infeasible.
At Amazon, machine learning has been key to many of our business processes, from recommendations to fraud detection, from inventory levels to book classification to abusive review detection. And there are many more application areas where we use machine learning extensively: search, autonomous drones, robotics in fulfillment centers, text and speech recognitions, etc.
Among machine learning algorithms, a class of algorithms called deep learning hascome to represent those algorithms that can absorb huge volumes of data and learn elegant and useful patterns within that data: faces inside photos, the meaning of a text, or the intent of a spoken word. A set of programming models has emerged to help developers define and train AI models with deep learning; along with open source frameworks that put deep learning in the hands of mere mortals. Some examples of popular deep learning frameworks that we support on AWS include Caffe, CNTK, MXNet, TensorFlow, Theano, and Torch.
Among all these popular frameworks, we have concluded that MXNet is the most scalable framework. We believe that the AI community would benefit from putting more effort behind MXNet. Today, we are announcing that MXNet will be our deep learning framework of choice. AWS will contribute code and improved documentation as well as invest in the ecosystem around MXNet. We will partner with other organizations to further advance MXNet.
AWS and Support for Deep Learning Frameworks
At AWS, we believe in giving choice to our customers. Our goal is to support our customers with tools, systems, and software of their choice by providing the right set of instances, software (AMIs), and managed services. Just like in Amazon RDS―where we support multiple open source engines like MySQL, PostgreSQL, and MariaDB, in the area of deep learning frameworks, we will support all popular deep learning frameworks by providing the best set of EC2 instances and appropriate software tools for them.
Amazon EC2, with its broad set of instance types and GPUs with large amounts of memory, has become the center of gravity for deep learning training. To that end, we recently made a set of tools available to make it as easy as possible to get started: a Deep Learning AMI, which comes pre-installed with the popular open source deep learning frameworks mentioned earlier; GPU-acceleration through CUDA drivers which are already installed, pre-configured, and ready to rock; and supporting tools such as Anaconda and Jupyter. Developers can also use the distributed Deep Learning CloudFormation template to spin up a scale-out, elastic cluster of P2 instances using this AMI for even larger training runs.
As Amazon and AWS continue to invest in several technologies powered by deep learning, we will continue to improve all of these frameworks in terms of usability, scalability, and features. However, we plan to contribute significantly to one in particular, MXNet.
Choosing a Deep Learning Framework
Developers, data scientists, and researchers consider three major factors when selecting a deep learning framework:
- The ability to scale to multiple GPUs (across multiple hosts) to train larger, more sophisticated models with larger, more sophisticated datasets. Deep learning models can take days or weeks to train, so even modest improvements here make a huge difference in the speed at which new models can be developed and evaluated.
- Development speed and programmability, especially the opportunity to use languages they are already familiar with, so that they can quickly build new models and update existing ones.
- Portability to run on a broad range of devices and platforms, because deep learning models have to run in many, many different places: from laptops and server farms with great networking and tons of computing power to mobiles and connected devices which are often in remote locations, with less reliable networking and considerably less computing power.
The same three things are important to developers at AWS and many of our customers. After a thorough evaluation, we have selected MXNet as our deep learning framework of choice , where we plan to use it broadly in existing and upcoming new services.
As part of that commitment, we will be actively promoting and supporting open source development through code contributions (we’ve made quite a few already), improving the developer experience and documentation online and on AWS, and investing in supporting tools for visualization, development, and migration from other frameworks.
Background on MXNet
MXNet is a fully featured, flexibly programmable, and ultra-scalable deep learning framework supporting state of the art in deep learning models, including convolutional neural networks (CNNs) and long short-term memory networks (LSTMs). MXNet has its roots in academia and came about through the collaboration and contributions of researchers at several top universities. Founding institutions include the University of Washington and Carnegie Mellon University.
“MXNet, born and bred here at CMU, is the most scalable framework for deep learning I have seen, and is a great example of what makes this area of computer science so beautiful - that you have different disciplines which all work so well together: imaginative linear algebra working in a novel way with massive distributed computation leading to a whole new ball game for deep learning. We’re excited about Amazon’s investment in MXNet, and can’t wait to see MXNet go from strength to strength” Andrew Moore – Dean of Computer Science at Carnegie Mellon University.
Scaling MXNet
The efficiency by which a deep learning framework scales out across multiple cores is one of its defining features. More efficient scaling allows you to significantly increase the rate at which you can train new models, or dramatically increase the sophistication of your model for the same amount of training time.
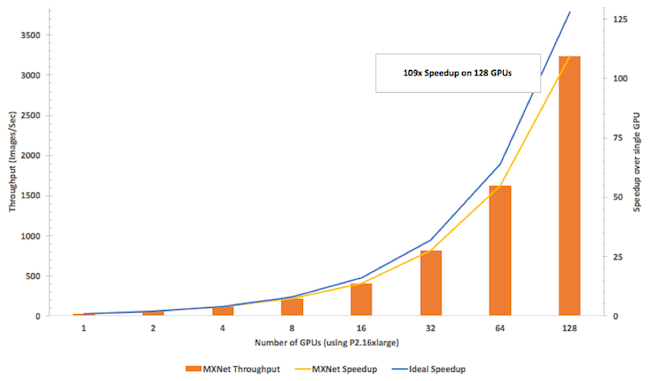
This is an area where MXNet shines: we trained a popular image analysis algorithm, Inception v3 (implemented in MXNet and running on P2 instances), using an increasing number of GPUs. Not only did MXNet have the fastest throughput of any library we evaluated (as measured by the number of images trained per second), but the throughput rose by almost the same rate as the number of GPUs used for training (with a scaling efficiency of 85%).
Developing With MXNet
In addition to scalability, MXNet offers the ability to both mix programming models (imperative and declarative), and code in a wide number of programming languages, including Python, C++, R, Scala, Julia, Matlab, and JavaScript.
Efficient Models & Portability In MXNet
Computational efficiency is important (and goes hand in hand with scalability) but nearly as important is the memory footprint. MXNet can consume as little as 4 GB of memory when serving deep networks with as many as 1000 layers. It is also portable across platforms, and the core library (with all dependencies) fits into a single C++ source file and can be compiled for both Android and iOS. You can even run it in your browser using the JavaScript extensions!
Learn more about MXNet
We’re excited about MXNet. If you would like to learn more, you can check out the MXNet home page, or GitHub repository for more information, and can get started right now, using the Deep Learning AMI, or on your own machine. We’ll also be hosting a Machine Learning “State of the Union” and a series of breakout sessions and workshops on using MXNet at AWS re:Invent on November 30th at the Mirage Hotel in Las Vegas.
It’s still day one for this new era of machine intelligence; in fact, we probably haven’t even woken up and had our first cup of coffee yet. With tools like MXNet (and the other deep learning frameworks), and services such as EC2, it’s going to be an exciting time.