Under the Hood of Amazon EC2 Container Service
In my last post about Amazon EC2 Container Service (Amazon ECS), I discussed the two key components of running modern distributed applications on a cluster: reliable state management and flexible scheduling. Amazon ECS makes building and running containerized applications simple, but how that happens is what makes Amazon ECS interesting. Today, I want to explore the Amazon ECS architecture and what this architecture enables. Below is a diagram of the basic components of Amazon ECS:
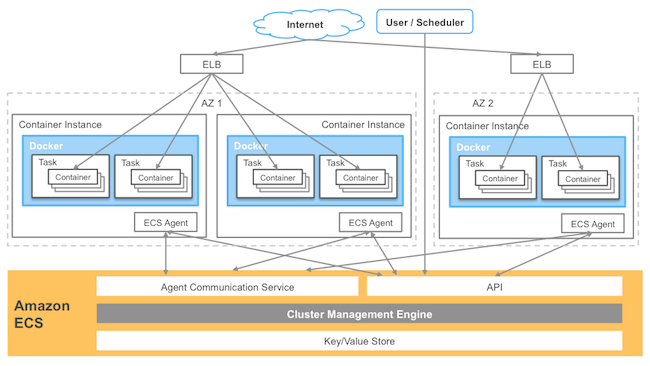
How we coordinate the cluster
Let’s talk about what Amazon ECS is actually doing. The core of Amazon ECS is the cluster manager, a backend service that handles the tasks of cluster coordination and state management. On top of the cluster manager sits various schedulers. Cluster management and container scheduling are components decoupled from each other allowing customers to use and build their own schedulers. A cluster is just a pool of compute resources available to a customer’s applications. The pool of resources, at this time, is the CPU, memory, and networking resources of Amazon EC2 instances as partitioned by containers. Amazon ECS coordinates the cluster through the Amazon ECS Container Agent running on each EC2 instance in the cluster. The agent allows Amazon ECS to communicate with the EC2 instances in the cluster to start, stop, and monitor containers as requested by a user or scheduler. The agent is written in Go, has a minimal footprint, and is available on GitHub under an Apache license. We encourage contributions and feedback is most welcome.
How we manage state
To coordinate the cluster, we need to have a single source of truth on the clusters themselves: EC2 instances in the clusters, tasks running on the EC2 instances, containers that make up a task, and resources available or occupied (e.g., networks ports, memory, CPU, etc). There is no way to successfully start and stop containers without an accurate knowledge of the state of the cluster. In order to solve this, state needs to be stored somewhere, so at the heart of any modern cluster manager is a key/value store.
This key/value store acts as the single source of truth for all information on the cluster (state, and all changes to state transitions) are entered and stored here. To be robust and scalable, this key/value store needs to be distributed for durability and availability, to protect against network partitions or hardware failures. But because the key/value store is distributed, making sure data is consistent and handling concurrent changes becomes more difficult, especially in an environment where state constantly changes (e.g., containers stopping and starting). As such, some form of concurrency control has to be put in place in order to make sure that multiple state changes don’t conflict. For example, if two developers request all the remaining memory resources from a certain EC2 instance for their container, only one container can actually receive those resources and the other would have to be told their request could not be completed.
To achieve concurrency control, we implemented Amazon ECS using one of Amazon’s core distributed systems primitives: a Paxos-based transactional journal based data store that keeps a record of every change made to a data entry. Any write to the data store is committed as a transaction in the journal with a specific order-based ID. The current value in a data store is the sum of all transactions made as recorded by the journal. Any read from the data store is only a snapshot in time of the journal. For a write to succeed, the write proposed must be the latest transaction since the last read. This primitive allows Amazon ECS to store its cluster state information with optimistic concurrency, which is ideal in environments where constantly changing data is shared (such as when representing the state of a shared pool of compute resources such as Amazon ECS). This architecture affords Amazon ECS high availability, low latency, and high throughput because the data store is never pessimistically locked.
Programmatic access through the API
Now that we have a key/value store, we can successfully coordinate the cluster and ensure that the desired number of containers is running because we have a reliable method to store and retrieve the state of the cluster. As mentioned earlier, we decoupled container scheduling from cluster management because we want customers to be able to take advantage of Amazon ECS’ state management capabilities. We have opened up the Amazon ECS cluster manager through a set of API actions that allow customers to access all the cluster state information stored in our key/value store in a structured manner.
Through ‘list’ commands, customers can retrieve the clusters under management, EC2 instances running in a specific cluster, running tasks, and the container configuration that make up the tasks (i.e., task definition). Through ‘describe’ commands, customers can retrieve details of specific EC2 instances and the resources available on each. Lastly, customers can start and stop tasks anywhere in the cluster. We recently ran a series of load tests on Amazon ECS, and we wanted to share some of the performance characteristics customers should expect when building applications on Amazon ECS.
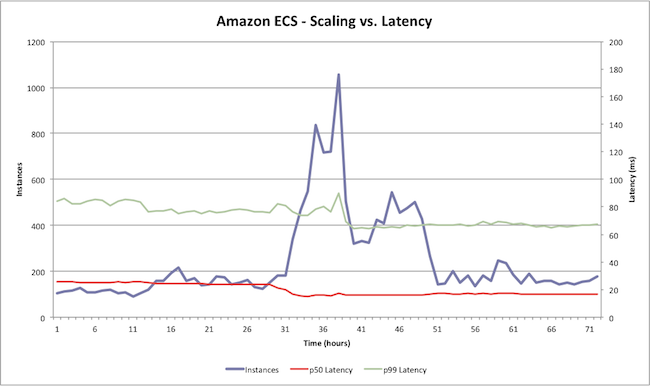
The above graph shows a load test where we added and removed instances from an Amazon ECS cluster and measured the 50th and 99th percentile latencies of the API call ‘DescribeTask’ over a seventy-two hour period. As you can see, the latency remains relatively jitter-free despite large fluctuations in the cluster size. Amazon ECS is able to scale with you no matter how large your cluster size – all without you needing to operate or scale a cluster manager.
This set of API actions form the basis of solutions that customers can build on top of Amazon ECS. A scheduler just provides logic around how, when, and where to start and stop containers. Amazon ECS’ architecture is designed to share the state of the cluster and allow customers to run as many varieties of schedulers (e.g., bin packing, spread, etc) as needed for their applications. The architecture enables the schedulers to query the exact state of the cluster and allocate resources from a common pool. The optimistic concurrency control in place allows each scheduler to receive the resources it requested without the possibility of resource conflicts. Customers have already created a variety of interesting solutions on top of Amazon ECS and we want to share a few compelling examples.
Hailo – Custom scheduling atop an elastic resource pool
Hailo is a free smartphone app, which allows people to hail licensed taxis directly to their location. Hailo has a global network of over 60,000 drivers and more than a million passengers. Hailo was founded in 2011 and has been built on AWS since Day 1. Over the past few years, Hailo has evolved from a monolithic application running in one AWS region to a microservices-based architecture running across multiple regions. Previously, each microservice ran atop a cluster of instances that was statically partitioned. The problem Hailo experienced was low resource utilization across each partition. This architecture wasn’t very scalable, and Hailo didn’t want its engineers to worry about the details of the infrastructure or the placement of the microservices.
Hailo decided it wanted to schedule containers based on service priority and other runtime metrics atop an elastic resource pool. They chose Amazon ECS as the cluster manager because it is a managed service that can easily enforce task state and fully exposes the cluster state via API calls. This allowed Hailo to build a custom scheduler with logic that met their specific application needs.
Remind – Platform as a service
Remind is a web and mobile application that enables teachers to text message students and stay in touch with parents. Remind has 24M users and over 1.5M teachers on its platform. It delivers 150M messages per month. Remind initially used Heroku to run its entire application infrastructure from message delivery engine, front-end API, and web client, to chat backends. Most of this infrastructure was deployed as a large monolithic application.
As the users grew, Remind wanted the ability to scale horizontally. So around the end of 2014, the engineering team started to explore moving towards a microservices architecture using containers. The team wanted to build a platform as a service (PaaS) that was compatible with the Heroku API on top of AWS. At first, the team looked to a few open-source solutions (e.g., CoreOS and Kubernetes) to handle the cluster management and container orchestration, but the engineering team was small so they didn’t have the time to manage the cluster infrastructure and keep the cluster highly available.
After briefly evaluating Amazon ECS, the team decided to build their PaaS on top of this service. Amazon ECS is fully managed and provides operational efficiency allowing engineering resources to just focus on developing and deploying applications; there are no clusters to manage or scale. In June, Remind open-sourced their PaaS solution on ECS as “Empire”. Remind saw large performance increases (e.g., latency and stability) with Empire as well as security benefits. Their plan over the next few months is to migrate over 90% of the core infrastructure onto Empire.
Amazon ECS – a fully managed platform
These are just a couple of the use cases we have seen from customers. The Amazon ECS architecture allows us to deliver a highly scalable, highly available, low latency container management service. The ability to access shared cluster state with optimistic concurrency through the API empowers customers to create whatever custom container solution they need. We have focused on removing the undifferentiated heavy lifting for customers. With Amazon ECS, there is no cluster manager to install or operate: customers can and should just focus on developing great applications.
We have delivered a number of features since our preview last November. Head over to Jeff Barr’s blog for a recap of the features we have added over the past year. Read our documentation and visit our console to get started. We still have a lot more on our roadmap and we value your feedback: please post questions and requests to our forum or on /r/aws.