Embrace event-driven computing: Amazon expands DynamoDB with streams, cross-region replication, and database triggers

In just three short years, Amazon DynamoDB has emerged as the backbone for many powerful Internet applications such as AdRoll, Druva, DeviceScape, and Battlecamp. Many happy developers are using DynamoDB to handle trillions of requests every day. I am excited to share with you that today we are expanding DynamoDB with streams, cross-region replication, and database triggers. In this blog post, I will explain how these three new capabilities empower you to build applications with distributed systems architecture and create responsive, reliable, and high-performance applications using DynamoDB that work at any scale.
DynamoDB Streams enables your application to get real-time notifications of your tables’ item-level changes. Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. DynamoDB Streams is the enabling technology behind two other features announced today: cross-region replication maintains identical copies of DynamoDB tables across AWS regions with push-button ease, and triggers execute AWS Lambda functions on streams, allowing you to respond to changing data conditions. Let me expand on each one of them.
DynamoDB Streams
DynamoDB Streams provides you with a time-ordered sequence, or change log, of all item-level changes made to any DynamoDB table. The stream is exposed via the familiar Amazon Kinesis interface. Using streams, you can apply the changes to a full-text search data store such as Elasticsearch, push incremental backups to Amazon S3, or maintain an up-to-date read cache.
I have heard from many of you that one of the common challenges you have is keeping DynamoDB data in sync with other data sources, such as search indexes or data warehouses. In traditional database architectures, database engines often run a small search engine or data warehouse engines on the same hardware as the database. However, the model of collocating all engines in a single database turns out to be cumbersome because the scaling characteristics of a transactional database are different from those of a search index or data warehouse. A more scalable option is to decouple these systems and build a pipe that connects these engines and feeds all change records from the source database to the data warehouse (e.g., Amazon Redshift) and Elasticsearch machines.
The velocity and variety of data that you are managing continues to increase, making your task of keeping up with the change more challenging as you want to manage the systems and applications in real time and respond to changing conditions. A common design pattern is to capture transactional and operational data (such as logs) that require high throughput and performance in DynamoDB, and provide periodic updates to search clusters and data warehouses. However, in the past, you had to write code to manage the data changes and deal with keeping the search engine and data warehousing engines in sync. For cost and manageability reasons, some developers have collocated the extract job, the search cluster, and data warehouses on the same box, leading to performance and scalability compromises. DynamoDB Streams simplifies and improves this design pattern with a distributed systems approach.
You can enable the DynamoDB Streams feature for a table with just a few clicks using the AWS Management Console, or you can use the DynamoDB API. Once configured, you can use an Amazon EC2 instance to read the stream using the Amazon Kinesis interface, and apply the changes in parallel to the search cluster, the data warehouse, and any number of data consumers. You can read the changes as they occur in real time or in batches as per your requirements. At launch, an item’s change record is available in the stream for 24 hours after it is created. An AWS Lambda function is a simpler option that you can use, as it only requires you to code the logic, set it, and forget it.
No matter which mechanism you choose to use, we make the stream data available to you instantly (latency in milliseconds) and how fast you want to apply the changes is up to you. Also, you can choose to program post-commit actions, such as running aggregate analytical functions or updating other dependent tables. This new design pattern allows you to keep your remote data consumers current with the core transactional data residing in DynamoDB at a frequency you desire and scale them independently, thereby leading to better availability, scalability, and performance. The Amazon Kinesis API model gives you a unified programming experience between your streaming apps written for Amazon Kinesis and DynamoDB Streams.
DynamoDB Cross-region Replication
Many modern database applications rely on cross-region replication for disaster recovery, minimizing read latencies (by making data available locally), and easy migration. Today, we are launching cross-region replication support for DynamoDB, enabling you to maintain identical copies of DynamoDB tables across AWS regions with just a few clicks. We have provided you with an application with a simple UI to set up and manage cross-region replication groups and build globally-distributed applications with ease. When you set up a replication group, DynamoDB automatically configures a stream between the tables, bootstraps the original data from source to target, and keeps the two in sync as the data changes. We have publicly shared the source code for the cross-region replication utility, which you can extend to build your own versions of data replication, search, or monitoring applications.
A great example for the application of this cross-region replication functionality is Mapbox, a popular mapping platform that enables developers to integrate location information into their mobile or online applications. Mapbox deals with location data from all over the globe and their key focus areas have been availability and performance. Having been part of the preview program, Jake Pruitt, Software Developer at Mapbox told us, “DynamoDB Streams unlocks cross-region replication - a critical feature that enabled us to fully migrate to DynamoDB. Cross-region replication allows us to distribute data across the world for redundancy and speed.” The new feature enables them to deliver better availability and improves the performance because they can access all needed data from the nearest data center.
DynamoDB Triggers
From the dawn of databases, the pull method has been the preferred model for interaction with a database. To retrieve data, applications are expected to make API calls and read the data. To get updates from a table, customers have to constantly poll the database with another API call. Relational databases use triggers as a mechanism to enable applications to respond to data changes. However, the execution of the triggers happens on the same machine as the one that runs the database and an errant trigger can wreak havoc on the whole database. In addition, such mechanisms do not scale well for fast-moving data sets and large databases.
To achieve a truly scalable, high-performance, and flexible system, we need to decouple the execution of triggers from the database and bring the data changes to the applications as they occur. Enter DynamoDB Triggers—an event-driven mechanism that enables developers to define Java or JavaScript functions that run outside the database in response to specific data changes in your DynamoDB tables. Specifically, these functions are configured and executed as AWS Lambda functions, giving you the ability to scale on the fly and only pay for the fractions of the computing seconds consumed. All you need to do is register the AWS Lambda function that needs to be executed in response to a specific data change in the DynamoDB table. Lambda and DynamoDB take care of the rest. DynamoDB creates a stream and pushes the data to the trigger code. Lambda automatically creates and manages the resources needed to handle the trigger. Since the Lambda function executes on hosts that are different from that of the DynamoDB table, both the DynamoDB table and Lambda function scale independently, thus isolating the risk of errant triggers.
Triggers are powerful mechanisms that react to events dynamically and in real time. Here is a practical real-world example of how triggers can be very useful to businesses: TOKYU HANDS is a fast-growing business with over 70 shops all over Japan. Their cloud architecture has two main components: a point-of-sales system and a merchandising system. The point-of-sales system records changes from all the purchases and stores them in DynamoDB. The merchandising system is used to manage the inventory and identify the right timing and quantity for refilling the inventory. The key challenge for them has been keeping these systems in sync constantly. After previewing DynamoDB Triggers, Naoyuki Yamazaki, Cloud Architect told us, “TOKYU HANDS is running in-store point-of-sales system backed by DynamoDB and various AWS services. We really like the full-managed service aspect of DynamoDB. With DynamoDB Streams and DynamoDB Triggers, we would now make our systems more connected and automated to respond faster to changing data such as inventory.” This new feature will help them manage inventory better to deliver a good customer experience while gaining more business efficiency.
You can also use triggers to power many modern Internet of Things (IoT) use cases. For example, you can program home sensors to write the state of temperature, water, gas, and electricity directly to DynamoDB. Then, you can set up Lambda functions to listen for updates on the DynamoDB tables and automatically notify users via mobile devices whenever specific levels of changes are detected.
Summing It All Up
If you are building mobile, ad-tech, gaming, web, or IOT applications, you can use DynamoDB to build globally distributed applications that deliver consistent and fast performance at any scale. With the three new features that I mentioned, you can now enrich those applications to consume high velocity data changes and react to updates in near real time. What this means to you is that, with DynamoDB, you are now empowered to create unique applications that have been difficult and expensive to build and manage before. Let me illustrate with an example.
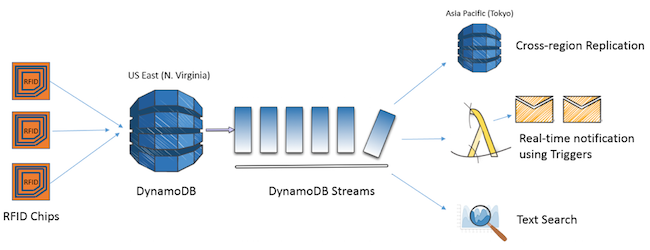
Let’s say that you are managing a supply-chain system with suppliers all over the globe. We all know the advantages that real-time inventory management can provide to such a system. Yet, building such a system that provides speed, scalability, and reliability at a low cost is not easy. On top of this, adding real-time updates for inventory management or extending the system with custom business logic with your own IT infrastructure is complex and costly.
This is where AWS and DynamoDB with cross-region replication, DynamoDB Triggers, and DynamoDB Streams can serve as a one-stop solution that handles all your requirements of scale, performance, and manageability, leaving you to focus on your business logic. All you need to do is to write the data from your products into DynamoDB. As illustrated in this example, if you use RFID tags on your products, you can directly feed the data from the scanners into DynamoDB. Then, you can use cross-region replication to sync the data across multiple AWS regions and bring the data close to your supply base. You can use triggers to monitor for inventory changes and send notifications in real time. To top it all off, you will have the flexibility to extend the DynamoDB Streams functionality for your custom business requirements. For example, you can feed the updates from the stream into a search index and use it for a custom search solution, thereby enabling your internal systems to locate the updates to inventory based on text searches. When you put it all together, you have a powerful business solution that scales to your needs, lets you pay only for what you provision, and helps you differentiate your offerings in the market and drive your business forward faster than before.
The combination of DynamoDB Streams, cross-region replication, and DynamoDB Triggers certainly offers immense potential to enable new and intriguing user scenarios with significantly less effort. You can learn more about these features on Jeff Barr’s blog. I am definitely eager to hear how each of you will use streams to drive more value for your businesses. Feel free to add a comment below and share your thoughts.